
The Infoleak that (Mostly) Wasn't
April 23, 2017
The following is an analysis of a recently fixed Linux kernel stack infoleak vulnerability existing from version 2.6.9 (Oct 2003) when compat-mode syscalls were added for set_mempolicy and mbind. It was reported and fixed publicly by Chris Salls On April 7th 2017 with a CC to security@kernel.org at: http://www.spinics.net/lists/linux-mm/msg125328.html and merged the following day via commit cf01fb9985e8deb25ccf0ea54d916b8871ae0e62. It was not marked with any "Fixes:" tag or stable@ CC, yet was backported to some stable kernels two days later. Historically, this is typical of upstream's attempts at avoiding CVE allocation and lowering the chance distros include the fix.
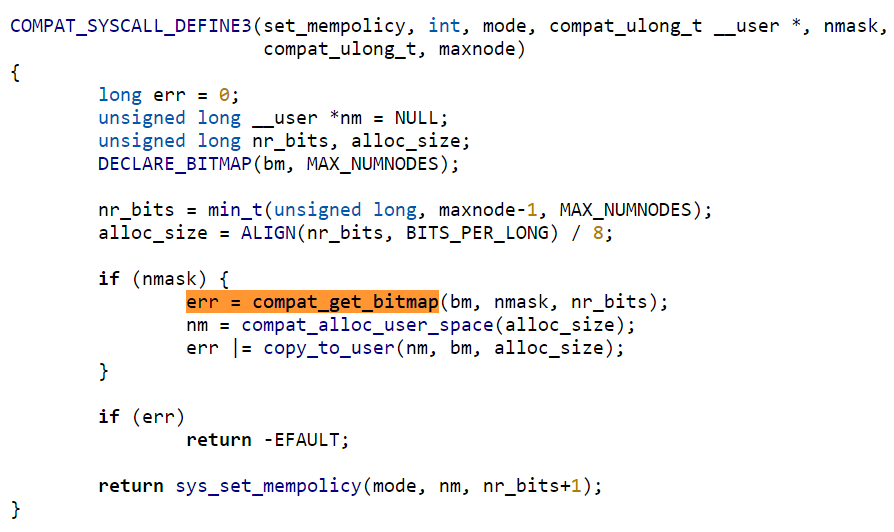
The vulnerability exists because compat_get_bitmap() could leave the nodemask on the kernel stack uninitialized in an error condition, and then instead of erroring out of the syscall immediately, it would proceed to copy the uninitialized nodemask to userland.

Generally with a 32-bit userland and with the limit on the size enforced prior to calling compat_get_bitmap(), the access_ok() shouldn't be able to fail. This means failing the call requires __get_user to fail, which can be done by providing some unmapped address. The zeroing behavior of __get_user isn't a problem for exploitation here because the temporary value gets thrown away instead of being set into the mask array before returning -EFAULT.

compat_alloc_user_space() in most cases works by decrementing a copy of the userland stack pointer by the requested allocation size and returning it. The image above shows the ARM64-specific implementation of the API. Since the leaked data is placed in this "allocation" via copy_to_user, it wouldn't normally be visible by high-level code -- any subsequent stack usage at lower depth would clobber the data. This suggests the vulnerability was likely found via static analysis or manual inspection by the reporter. For exploitation purposes, using assembly to prime the region and search for leaked data after the syscall provides more determinism.
The size of the leak depends on the value of CONFIG_NODES_SHIFT. Values up to 6 would have 8 bytes of uninitialized stack, other distros setting this to 10 would have 128 bytes of uninitialized stack. If it weren't for the next issue, this would be more than enough to defeat KASLR on any 64-bit Linux kernel (not to suggest that these kinds of individual leaks are necessary to defeat KASLR when generic timing attacks are always feasible).
Unfortunately (for an attacker), only a handful of architectures have wired up support for the compat versions of the set_mempolicy and mbind syscalls. Specifically, of recent versions this includes arm64, sparc64, s390, powerpc64, and mips64. So the vulnerability can't be triggered on x86-64 systems. On the architectures that do have support for these syscalls, CONFIG_NUMA is also required for the routines to actually be built into the kernel. Support for enabling CONFIG_NUMA on arm64 however was only added relatively recently in April of 2016, and it's unlikely to be enabled in the few kernel versions where that support exists.
Assuming we had a rare unicorn of a system where the vulnerable syscalls could actually be reached, exploitation would proceed as follows:
- Run a random syscall without system side effects
- Memset the N bytes below the stack pointer
- Invoke the 32-bit version of set_mempolicy, setting the arguments as:
mode: anything
nmask: address of unmapped memory (0xffffffff for instance) as this will cause the compat_get_bitmap() call to fail
maxnode: 0xffffffff (the min_t() operation performed by the compat version of the syscall will ensure that MAX_NUMNODES will be chosen and the largest possible infoleak will be performed, 8 to 128 bytes in practice) - Inspect the N bytes memory below the stack pointer (assuming you did direct syscall invocation for step 3) for non-zero quadwords. With a variety of syscalls in step 1, a kernel address is almost surely to be found.
So a 13 year old infoleak that as of yet has no CVE (by design, due to upstream's handling process) ends up not being very important. With a policy that hinders distro adoption of security fixes, however, this story could have just as likely ended with the opposite result -- and without a blog post like this, one would likely have never heard about it.
Update: the article claimed no CVE existed at time of publication, but one was indeed assigned CVE-2017-7616 on April 10th. I apologize for this mistake -- in my search for the commit message there was clearly a result on the first page that I must have overlooked at the time. If you're interested in seeing vulnerabilities fixed without CVEs, there are a plethora of other examples (see here for some), just not this specific instance.
Update 2: the size of the leak with CONFIG_NODES_SHIFT=10 was incorrect. I originally reported 16 due to an extra division, but as reported by Vladis Dronov of Red Hat, it's in fact 128 bytes. He also correctly noted that powerpc64 is also affected.
Of interesting note is Red Hat gives this a CVSSv3 score of 5.5 and lists their kernels as affected, when as demonstrated by the analysis above the vulnerable code isn't even accessible on x64 kernels. This may be a reflection of the fact that the sheer volume of Linux kernel vulnerabilities results in very little exploitation analysis being performed on individiual vulnerabilities these days.
Until next time,
-Brad